Microsoft DP-203 Übungsprüfungen
Zuletzt aktualisiert am 26.04.2025- Prüfungscode: DP-203
- Prüfungsname: Data Engineering on Microsoft Azure
- Zertifizierungsanbieter: Microsoft
- Zuletzt aktualisiert am: 26.04.2025
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You schedule an Azure Databricks job that executes an R notebook, and then inserts the data into the data warehouse.
Does this meet the goal?
- A . Yes
- B . No
Note: The question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it As a result these questions will not appear in the review screen. You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a dairy process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes a mapping data low. and then inserts the data into the data warehouse.
Does this meet the goal?
- A . Yes
- B . No
HOTSPOT
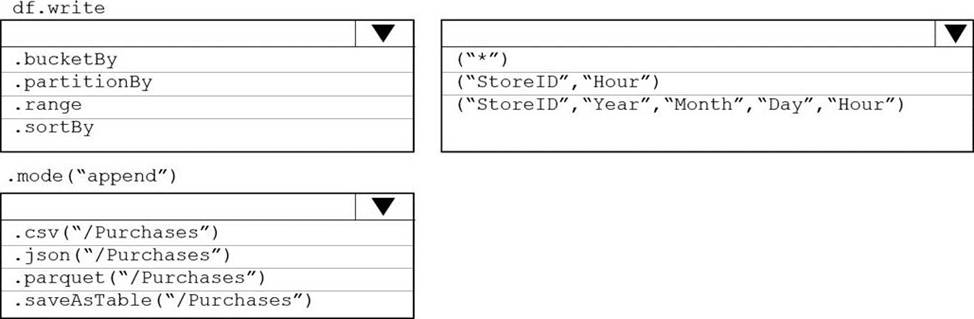
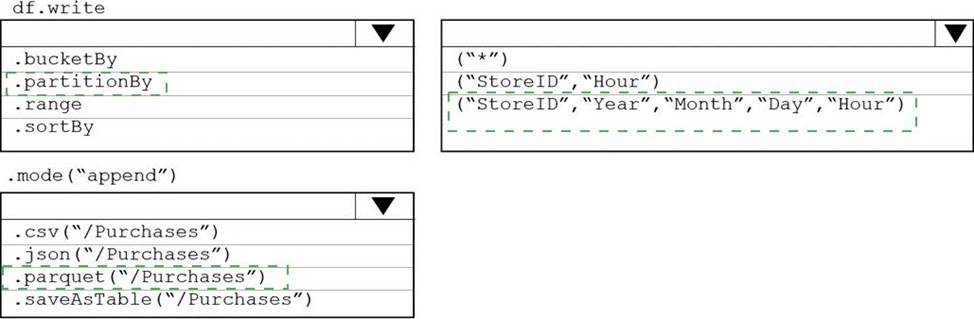
You plan to develop a dataset named Purchases by using Azure databricks Purchases will contain the following columns:
• ProductID
• ItemPrice
• lineTotal
• Quantity
• StorelD
• Minute
• Month
• Hour
• Year
• Day
You need to store the data to support hourly incremental load pipelines that will vary for each StoreID. the solution must minimize storage costs.
How should you complete the rode? To answer, select the appropriate options In the answer area. NOTE: Each correct selection is worth one point.
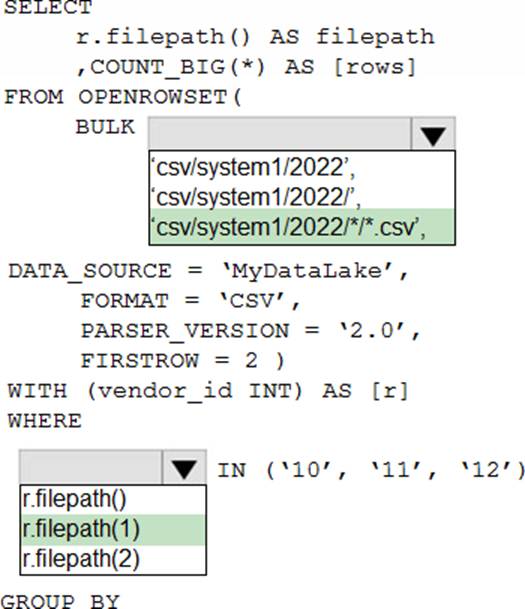
HOTSPOT
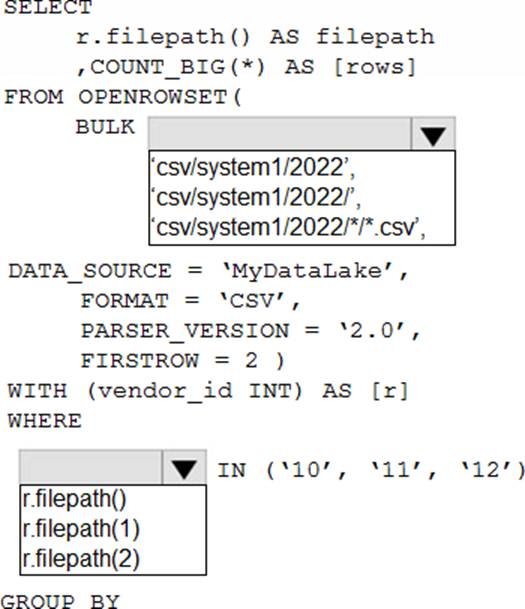
You have an Azure Data Lake Storage account that contains one CSV file per hour for January 1, 2020, through January 31, 2023. The files are partitioned by using the following folder structure. csv/system1/{year}/{month)/{filename).csv
You need to query the files by using an Azure Synapse Analytics serverless SQL pool The solution must return the row count of each file created during the last three months of 2022.
How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to create an Azure Databricks workspace that has a tiered structure.
The workspace will contain the following three workloads:
✑ A workload for data engineers who will use Python and SQL.
✑ A workload for jobs that will run notebooks that use Python, Scala, and SOL.
✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R.
The enterprise architecture team at your company identifies the following standards for Databricks environments:
✑ The data engineers must share a cluster.
✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster.
✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists.
You need to create the Databricks clusters for the workloads.
Solution: You create a High Concurrency cluster for each data scientist, a High Concurrency cluster for the data engineers, and a Standard cluster for the jobs.
Does this meet the goal?
- A . Yes
- B . No
You have an Azure Data Factory pipeline named pipeline1 that includes a Copy activity named Copy1.
Copy1 has the following configurations:
• The source of Copy1 is a table in an on-premises Microsoft SQL Server instance that is accessed by using a linked service connected via a self-hosted integration runtime.
• The sink of Copy1 uses a table in an Azure SQL database that is accessed by using a linked service connected via an Azure integration runtime.
You need to maximize the amount of compute resources available to Copy1. The solution must minimize administrative effort.
What should you do?
- A . Scale up the data flow runtime of the Azure integration runtime.
- B . Scale up the data flow runtime of the Azure integration runtime and scale out the self-hosted integration runtime.
- C . Scale out the self-hosted integration runtime.
You use Azure Stream Analytics to receive Twitter data from Azure Event Hubs and to output the data to an Azure Blob storage account.
You need to output the count of tweets from the last five minutes every minute.
Which windowing function should you use?
- A . Sliding
- B . Session
- C . Tumbling
- D . Hopping
You have an Azure subscription that contains an Azure Data Lake Storage account named myaccount1. The myaccount1 account contains two containers named container1 and contained. The subscription is linked to an Azure Active Directory (Azure AD) tenant that contains a security group named Group1.
You need to grant Group1 read access to contamer1. The solution must use the principle of least privilege.
Which role should you assign to Group1?
- A . Storage Blob Data Reader for container1
- B . Storage Table Data Reader for container1
- C . Storage Blob Data Reader for myaccount1
- D . Storage Table Data Reader for myaccount1
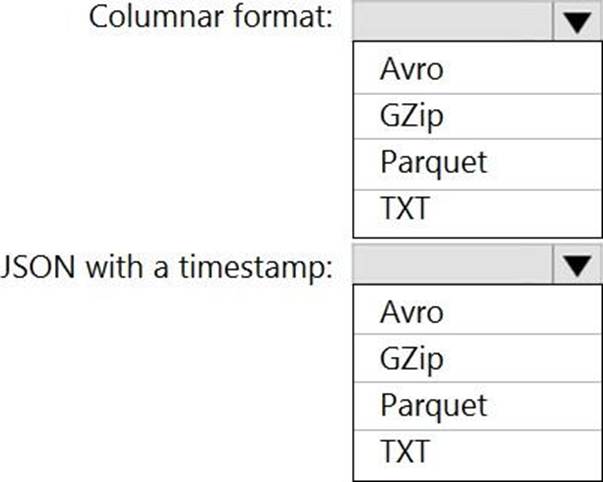
HOTSPOT
You need to output files from Azure Data Factory.
Which file format should you use for each type of output? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

HOTSPOT
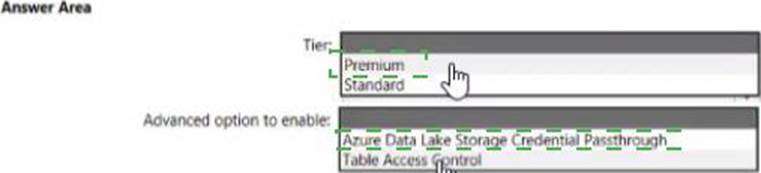
You need to implement an Azure Databricks cluster that automatically connects to Azure Data lake Storage Gen2 by using Azure Active Directory (Azure AD) integration.
How should you configure the new clutter? To answer, select the appropriate options in the answers area. NOTE: Each correct selection is worth one point.