Amazon MLA-C01 Übungsprüfungen
Zuletzt aktualisiert am 26.04.2025- Prüfungscode: MLA-C01
- Prüfungsname: AWS Certified Machine Learning Engineer - Associate
- Zertifizierungsanbieter: Amazon
- Zuletzt aktualisiert am: 26.04.2025
Which of the following is correct regarding the training set, validation set, and test set used in the context of machine learning? (Select two)
- A . Test set is used to determine how well the model generalizes
- B . Test set is used for hyperparameter tuning
- C . Test sets are optional
- D . Validation sets are optional
- E . Validation set is used to determine how well the model generalizes
You are a Cloud Financial Manager at a SaaS company that uses various AWS services to run its applications and machine learning workloads. Your management team has asked you to reduce overall AWS spending while ensuring that critical applications remain highly available and performant. To achieve this, you need to use AWS cost analysis tools to monitor spending, identify cost-saving opportunities, and optimize resource utilization across the organization.
Which of the following actions can you perform using the appropriate AWS cost analysis tools to achieve your goal of reducing costs and optimizing AWS resource utilization? (Select two)
- A . Use AWS Cost Explorer to analyze historical spending patterns, identify cost trends, and forecast future costs to help with budgeting and planning
- B . Use AWS Cost Explorer to automatically delete unused resources across your AWS environment, ensuring that no unnecessary costs are incurred
- C . Leverage AWS Trusted Advisor to receive recommendations for cost optimization, such as identifying underutilized or idle resources, and reserved instance purchasing opportunities
- D . Use AWS Cost Explorer to set custom budgets for cost and usage to govern costs across your organization and receive alerts when costs exceed your defined thresholds
- E . Leverage AWS Trusted Advisor to directly modify and reconfigure resources based on cost optimization recommendations without manual intervention
You are preparing a dataset for training a machine learning model using SageMaker Data Wrangler. The dataset has several missing values spread across different columns, and these columns contain numeric data. Before training the model, it is essential to handle these missing values to ensure the model performs optimally. The goal is to replace the missing values in each numeric column with the mean of that column.
Which transformation in SageMaker Data Wrangler should you apply to replace the missing values in numeric columns with the mean of those columns?
- A . Encode
- B . Impute
- C . Scale
- D . Drop
What is uncertainty in the context of machine learning?
- A . The clarity of the model’s decision-making process
- B . The speed of the algorithm
- C . The amount of data available for training
- D . An imperfect outcome
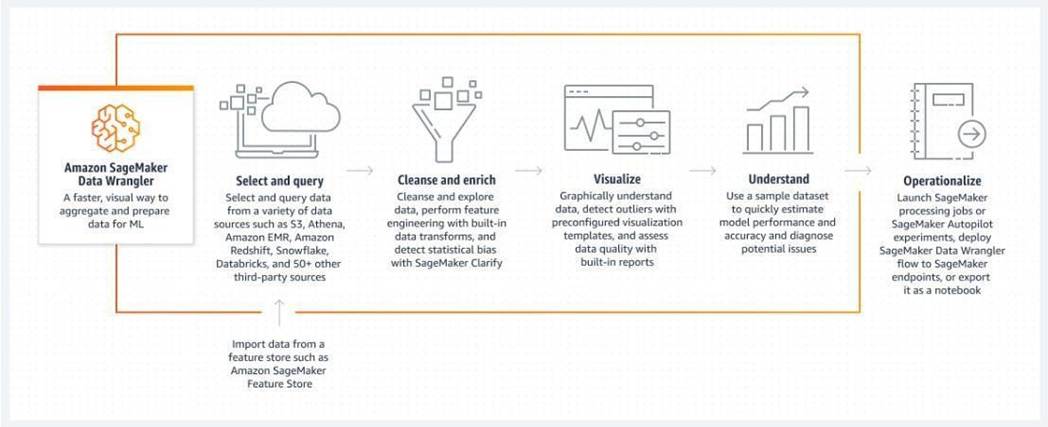
A company stores its training datasets on Amazon S3 in the form of tabular data running into millions of rows. The company needs to prepare this data for Machine Learning jobs. The data preparation involves data selection, cleansing, exploration, and visualization using a single visual interface.
Which Amazon SageMaker service is the best fit for this requirement?
- A . Amazon SageMaker Feature Store
- B . Amazon SageMaker Data Wrangler
- C . SageMaker Model Dashboard
- D . Amazon SageMaker Clarify
You are a DevOps engineer responsible for maintaining a serverless machine learning application that provides real-time predictions using AWS Lambda. Recently, users have reported increased latency when interacting with the application, especially during peak usage hours. You need to quickly identify the root cause of the latency and resolve the performance issues to ensure the application remains responsive.
Which combination of monitoring and observability tools is the MOST EFFECTIVE for troubleshooting the latency and performance issues in this serverless application?
- A . Use AWS X-Ray to trace requests across the entire application, identify bottlenecks, and visualize the end-to-end latency for each request. Combine this with Amazon CloudWatch Lambda Insights to monitor the Lambda function’s memory usage, CPU usage, and invocation times
- B . Use Amazon CloudWatch Alarms to set thresholds for Lambda duration and error rates, and configure AWS X-Ray to periodically sample traces from the application for analysis
- C . Enable detailed monitoring in Amazon CloudWatch to track Lambda invocations, errors, and throttles, and manually inspect the Lambda code to identify performance bottlenecks
- D . Deploy Amazon CloudWatch Logs Insights to query and analyze the application logs for errors, and use AWS Config to review recent changes to the infrastructure that might have introduced latency
You are a Senior ML Engineer at a global logistics company that heavily relies on machine learning models for optimizing delivery routes, predicting demand, and detecting anomalies in real-time. The company is rapidly expanding, and you are tasked with building a maintainable, scalable, and cost-effective ML infrastructure that can handle increasing data volumes and evolving model requirements. You must implement best practices to ensure that the infrastructure can support ongoing development, deployment, monitoring, and scaling of multiple models across different regions.
Which of the following strategies should you implement to create a maintainable, scalable, and cost-effective ML infrastructure for your company using AWS services? (Select three)
- A . Provision fixed resources for each model to avoid unexpected costs, ensuring that the infrastructure is always available for each model
- B . Store all model artifacts and data in Amazon CodeCommit for version control and managing changes over time
- C . Use a monolithic architecture to manage all machine learning models in a single environment, simplifying management and reducing overhead
- D . Store all model artifacts and data in Amazon S3, and use versioning to manage changes over time, ensuring that models can be easily rolled back if needed
- E . Implement a microservices-based architecture with Amazon SageMaker endpoints, where each model is deployed independently, allowing for isolated scaling and updates
- F . Utilize infrastructure as code (IaC) with AWS CloudFormation to automate the deployment and management of ML resources, making it easy to replicate and scale infrastructure across regions
You are a machine learning engineer at a fintech company that has developed several models for various use cases, including fraud detection, credit scoring, and personalized marketing. Each model has different performance and deployment requirements. The fraud detection model requires real-time predictions with low latency and needs to scale quickly based on incoming transaction volumes. The credit scoring model is computationally intensive but can tolerate batch processing with slightly higher latency. The personalized marketing model needs to be triggered by events and doesn’t require constant availability.
Given these varying requirements, which deployment target is the MOST SUITABLE for each model?
- A . Deploy the fraud detection model using AWS Lambda for serverless, on-demand execution, deploy the credit scoring model on Amazon EKS for scalable batch processing, and deploy the personalized marketing model on SageMaker endpoints to handle event-driven inference
- B . Deploy the fraud detection model using SageMaker endpoints for low-latency, real-time predictions, deploy the credit scoring model on Amazon ECS for batch processing, and deploy the personalized marketing model using AWS Lambda for event-driven execution
- C . Deploy all three models on a single Amazon EKS cluster to take advantage of Kubernetes orchestration, ensuring consistent management and scaling across different use cases
- D . Deploy the fraud detection model on Amazon ECS for auto-scaling based on demand, deploy the credit scoring model using SageMaker endpoints for real-time scoring, and deploy the personalized marketing model on Amazon EKS for event-driven processing
Why is it important to estimate the amount of uncertainty in an ML model?
- A . To improve the model’s computational efficiency
- B . To increase the speed of data processing
- C . To reduce the amount of training data needed
- D . To avoid potential misinterpretations of life and property
You are a data scientist working for an e-commerce company that wants to implement personalized product recommendations for its users. The company has a large dataset of user interactions, including clicks, purchases, and reviews. The goal is to create a recommendation system that can scale to millions of users while providing real-time recommendations based on user behavior. You need to choose the most appropriate built-in algorithm in Amazon SageMaker to achieve this goal.
Given the requirements, which of the following Amazon SageMaker built-in algorithms is the MOST SUITABLE for this use case?
- A . XGBoost Algorithm to rank the products based on user behavior and demographic features
- B . K-Means Algorithm to cluster users into segments and recommend products based on these segments
- C . Factorization Machines Algorithm to model user-item interactions for collaborative filtering
- D . BlazingText Algorithm to analyze the text in user reviews and identify product similarities