Databricks Databricks Certified Data Engineer Professional Übungsprüfungen
Zuletzt aktualisiert am 21.06.2026- Prüfungscode: Databricks Certified Data Engineer Professional
- Prüfungsname: Databricks Certified Data Engineer Professional Exam
- Zertifizierungsanbieter: Databricks
- Zuletzt aktualisiert am: 21.06.2026
Although the Databricks Utilities Secrets module provides tools to store sensitive credentials and avoid accidentally displaying them in plain text users should still be careful with which credentials are stored here and which users have access to using these secrets.
Which statement describes a limitation of Databricks Secrets?
- A . Because the SHA256 hash is used to obfuscate stored secrets, reversing this hash will display the value in plain text.
- B . Account administrators can see all secrets in plain text by logging on to the Databricks Accounts console.
- C . Secrets are stored in an administrators-only table within the Hive Metastore; database administrators have permission to query this table by default.
- D . Iterating through a stored secret and printing each character will display secret contents in plain text.
- E . The Databricks REST API can be used to list secrets in plain text if the personal access token has proper credentials.
Which is a key benefit of an end-to-end test?
- A . It closely simulates real world usage of your application.
- B . It pinpoint errors in the building blocks of your application.
- C . It provides testing coverage for all code paths and branches.
- D . It makes it easier to automate your test suite
The data architect has mandated that all tables in the Lakehouse should be configured as external Delta Lake tables.
Which approach will ensure that this requirement is met?
- A . Whenever a database is being created, make sure that the location keyword is used
- B . When configuring an external data warehouse for all table storage. leverage Databricks for all ELT.
- C . Whenever a table is being created, make sure that the location keyword is used.
- D . When tables are created, make sure that the external keyword is used in the create table statement.
- E . When the workspace is being configured, make sure that external cloud object storage has been mounted.
A junior data engineer is working to implement logic for a Lakehouse table named silver_device_recordings. The source data contains 100 unique fields in a highly nested JSON structure.
The silver_device_recordings table will be used downstream to power several production monitoring dashboards and a production model. At present, 45 of the 100 fields are being used in at least one of these applications.
The data engineer is trying to determine the best approach for dealing with schema declaration given the highly-nested structure of the data and the numerous fields.
Which of the following accurately presents information about Delta Lake and Databricks that may impact their decision-making process?
- A . The Tungsten encoding used by Databricks is optimized for storing string data; newly-added native support for querying JSON strings means that string types are always most efficient.
- B . Because Delta Lake uses Parquet for data storage, data types can be easily evolved by just modifying file footer information in place.
- C . Human labor in writing code is the largest cost associated with data engineering workloads; as such, automating table declaration logic should be a priority in all migration workloads.
- D . Because Databricks will infer schema using types that allow all observed data to be processed, setting types manually provides greater assurance of data quality enforcement.
- E . Schema inference and evolution on .Databricks ensure that inferred types will always accurately match the data types used by downstream systems.
The data architect has mandated that all tables in the Lakehouse should be configured as external (also known as "unmanaged") Delta Lake tables.
Which approach will ensure that this requirement is met?
- A . When a database is being created, make sure that the LOCATION keyword is used.
- B . When configuring an external data warehouse for all table storage, leverage Databricks for all ELT.
- C . When data is saved to a table, make sure that a full file path is specified alongside the Delta format.
- D . When tables are created, make sure that the EXTERNAL keyword is used in the CREATE TABLE statement.
- E . When the workspace is being configured, make sure that external cloud object storage has been mounted.
A user wants to use DLT expectations to validate that a derived table report contains all records from the source, included in the table validation_copy.
The user attempts and fails to accomplish this by adding an expectation to the report table definition.
Which approach would allow using DLT expectations to validate all expected records are present in
this table?
- A . Define a SQL UDF that performs a left outer join on two tables, and check if this returns null values for report key values in a DLT expectation for the report table.
- B . Define a function that performs a left outer join on validation_copy and report and report, and check against the result in a DLT expectation for the report table
- C . Define a temporary table that perform a left outer join on validation_copy and report, and define an expectation that no report key values are null
- D . Define a view that performs a left outer join on validation_copy and report, and reference this view in DLT expectations for the report table
The DevOps team has configured a production workload as a collection of notebooks scheduled to run daily using the Jobs Ul. A new data engineering hire is onboarding to the team and has requested access to one of these notebooks to review the production logic.
What are the maximum notebook permissions that can be granted to the user without allowing accidental changes to production code or data?
- A . Can manage
- B . Can edit
- C . Can run
- D . Can Read
Which statement describes Delta Lake optimized writes?
- A . A shuffle occurs prior to writing to try to group data together resulting in fewer files instead of each executor writing multiple files based on directory partitions.
- B . Optimized writes logical partitions instead of directory partitions partition boundaries are only represented in metadata fewer small files are written.
- C . An asynchronous job runs after the write completes to detect if files could be further compacted; yes, an OPTIMIZE job is executed toward a default of 1 GB.
- D . Before a job cluster terminates, OPTIMIZE is executed on all tables modified during the most recent job.
A nightly job ingests data into a Delta Lake table using the following code:
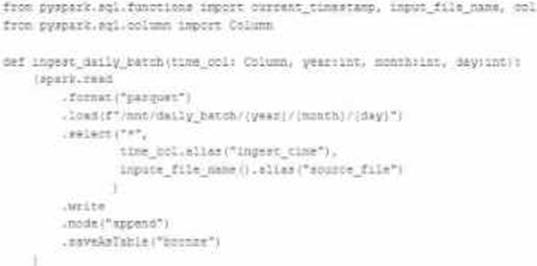
The next step in the pipeline requires a function that returns an object that can be used to manipulate new records that have not yet been processed to the next table in the pipeline.
Which code snippet completes this function definition?
A) def new_records():
B) return spark.readStream.table("bronze")
C) return spark.readStream.load("bronze")
D) return spark.read.option("readChangeFeed", "true").table ("bronze")
E)

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
The business intelligence team has a dashboard configured to track various summary metrics for retail stories. This includes total sales for the previous day alongside totals and averages for a variety of time periods.
The fields required to populate this dashboard have the following schema:
For Demand forecasting, the Lakehouse contains a validated table of all itemized sales updated ncrementally in near real-time. This table named products_per_order, includes the following fields:
Because reporting on long-term sales trends is less volatile, analysts using the new dashboard only require data to be refreshed once daily. Because the dashboard will be queried interactively by many users throughout a normal business day, it should return results quickly and reduce total compute associated with each materialization.
Which solution meets the expectations of the end users while controlling and limiting possible costs?
- A . Use the Delta Cache to persists the products_per_order table in memory to quickly the dashboard with each query.
- B . Populate the dashboard by configuring a nightly batch job to save the required to quickly update the dashboard with each query.
- C . Use Structure Streaming to configure a live dashboard against the products_per_order table within a Databricks notebook.
- D . Define a view against the products_per_order table and define the dashboard against this view.