Databricks Databricks Certified Data Engineer Professional Übungsprüfungen
Zuletzt aktualisiert am 03.04.2026- Prüfungscode: Databricks Certified Data Engineer Professional
- Prüfungsname: Databricks Certified Data Engineer Professional Exam
- Zertifizierungsanbieter: Databricks
- Zuletzt aktualisiert am: 03.04.2026
Incorporating unit tests into a PySpark application requires upfront attention to the design of your jobs, or a potentially significant refactoring of existing code.
Which statement describes a main benefit that offset this additional effort?
- A . Improves the quality of your data
- B . Validates a complete use case of your application
- C . Troubleshooting is easier since all steps are isolated and tested individually
- D . Yields faster deployment and execution times
- E . Ensures that all steps interact correctly to achieve the desired end result
A Data engineer wants to run unit’s tests using common Python testing frameworks on python functions defined across several Databricks notebooks currently used in production.
How can the data engineer run unit tests against function that work with data in production?
- A . Run unit tests against non-production data that closely mirrors production
- B . Define and unit test functions using Files in Repos
- C . Define units test and functions within the same notebook
- D . Define and import unit test functions from a separate Databricks notebook
A production cluster has 3 executor nodes and uses the same virtual machine type for the driver and executor.
When evaluating the Ganglia Metrics for this cluster, which indicator would signal a bottleneck caused by code executing on the driver?
- A . The five Minute Load Average remains consistent/flat
- B . Bytes Received never exceeds 80 million bytes per second
- C . Total Disk Space remains constant
- D . Network I/O never spikes
- E . Overall cluster CPU utilization is around 25%
Which of the following technologies can be used to identify key areas of text when parsing Spark Driver log4j output?
- A . Regex
- B . Julia
- C . pyspsark.ml.feature
- D . Scala Datasets
- E . C++
The data governance team is reviewing user for deleting records for compliance with GDPR.
The following logic has been implemented to propagate deleted requests from the user_lookup table to the user aggregate table.
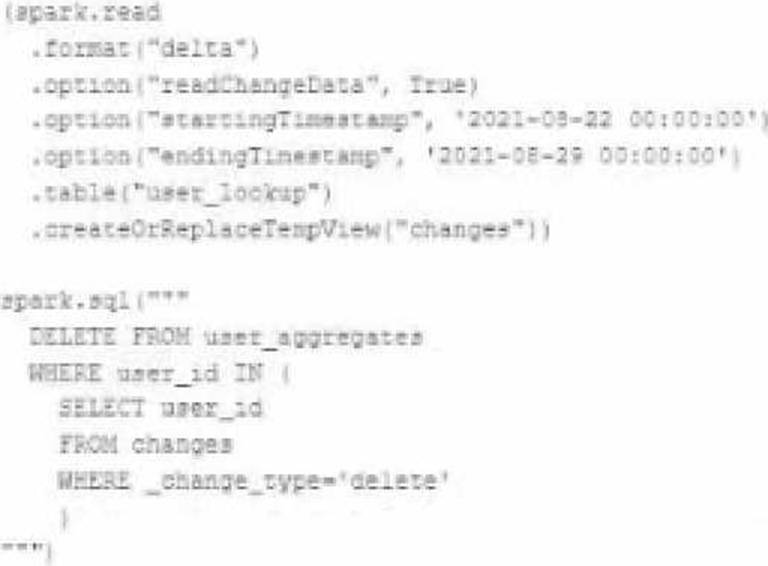
Assuming that user_id is a unique identifying key and that all users have requested deletion have been removed from the user_lookup table, which statement describes whether successfully executing the above logic guarantees that the records to be deleted from the user_aggregates table are no longer accessible and why?
- A . No: files containing deleted records may still be accessible with time travel until a BACUM command is used to remove invalidated data files.
- B . Yes: Delta Lake ACID guarantees provide assurance that the DELETE command successed fully and permanently purged these records.
- C . No: the change data feed only tracks inserts and updates not deleted records.
- D . No: the Delta Lake DELETE command only provides ACID guarantees when combined with the MERGE INTO command
In order to prevent accidental commits to production data, a senior data engineer has instituted a policy that all development work will reference clones of Delta Lake tables. After testing both deep and shallow clone, development tables are created using shallow clone.
A few weeks after initial table creation, the cloned versions of several tables implemented as Type 1 Slowly Changing Dimension (SCD) stop working. The transaction logs for the source tables show that vacuum was run the day before.
Why are the cloned tables no longer working?
- A . The data files compacted by vacuum are not tracked by the cloned metadata; running refresh on the cloned table will pull in recent changes.
- B . Because Type 1 changes overwrite existing records, Delta Lake cannot guarantee data consistency for cloned tables.
- C . The metadata created by the clone operation is referencing data files that were purged as invalid by the vacuum command
- D . Running vacuum automatically invalidates any shallow clones of a table; deep clone should always be used when a cloned table will be repeatedly queried.
A Delta Lake table was created with the below query:
Realizing that the original query had a typographical error, the below code was executed:
ALTER TABLE prod.sales_by_stor RENAME TO prod.sales_by_store
Which result will occur after running the second command?
- A . The table reference in the metastore is updated and no data is changed.
- B . The table name change is recorded in the Delta transaction log.
- C . All related files and metadata are dropped and recreated in a single ACID transaction.
- D . The table reference in the metastore is updated and all data files are moved.
- E . A new Delta transaction log Is created for the renamed table.
A member of the data engineering team has submitted a short notebook that they wish to schedule as part of a larger data pipeline. Assume that the commands provided below produce the logically correct results when run as presented.

Which command should be removed from the notebook before scheduling it as a job?
- A . Cmd 2
- B . Cmd 3
- C . Cmd 4
- D . Cmd 5
- E . Cmd 6
A Delta Lake table in the Lakehouse named customer_parsams is used in churn prediction by the machine learning team. The table contains information about customers derived from a number of upstream sources. Currently, the data engineering team populates this table nightly by overwriting the table with the current valid values derived from upstream data sources.
Immediately after each update succeeds, the data engineer team would like to determine the difference between the new version and the previous of the table.
Given the current implementation, which method can be used?
- A . Parse the Delta Lake transaction log to identify all newly written data files.
- B . Execute DESCRIBE HISTORY customer_churn_params to obtain the full operation metrics for the update, including a log of all records that have been added or modified.
- C . Execute a query to calculate the difference between the new version and the previous version using Delta Lake’s built-in versioning and time travel functionality.
- D . Parse the Spark event logs to identify those rows that were updated, inserted, or deleted.
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df. The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Incremental state information should be maintained for 10 minutes for late-arriving data.
Streaming DataFrame df has the following schema:
"device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT"
Code block:
Choose the response that correctly fills in the blank within the code block to complete this task.
- A . withWatermark("event_time", "10 minutes")
- B . awaitArrival("event_time", "10 minutes")
- C . await("event_time + ‘10 minutes’")
- D . slidingWindow("event_time", "10 minutes")
- E . delayWrite("event_time", "10 minutes")