Databricks Databricks Certified Data Engineer Professional Übungsprüfungen
Zuletzt aktualisiert am 01.04.2026- Prüfungscode: Databricks Certified Data Engineer Professional
- Prüfungsname: Databricks Certified Data Engineer Professional Exam
- Zertifizierungsanbieter: Databricks
- Zuletzt aktualisiert am: 01.04.2026
The data engineering team has configured a Databricks SQL query and alert to monitor the values in
a Delta Lake table. The recent_sensor_recordings table contains an identifying sensor_id alongside the timestamp and temperature for the most recent 5 minutes of recordings.
The below query is used to create the alert:
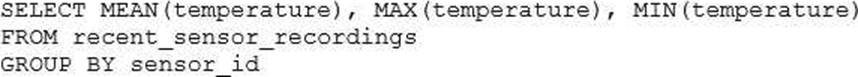
The query is set to refresh each minute and always completes in less than 10 seconds. The alert is set to trigger when mean (temperature) > 120. Notifications are triggered to be sent at most every 1 minute.
If this alert raises notifications for 3 consecutive minutes and then stops, which statement must be true?
- A . The total average temperature across all sensors exceeded 120 on three consecutive executions of the query
- B . The recent_sensor_recordingstable was unresponsive for three consecutive runs of the query
- C . The source query failed to update properly for three consecutive minutes and then restarted
- D . The maximum temperature recording for at least one sensor exceeded 120 on three consecutive executions of the query
- E . The average temperature recordings for at least one sensor exceeded 120 on three consecutive executions of the query
Two of the most common data locations on Databricks are the DBFS root storage and external object storage mounted with dbutils.fs.mount().
Which of the following statements is correct?
- A . DBFS is a file system protocol that allows users to interact with files stored in object storage using syntax and guarantees similar to Unix file systems.
- B . By default, both the DBFS root and mounted data sources are only accessible to workspace administrators.
- C . The DBFS root is the most secure location to store data, because mounted storage volumes must have full public read and write permissions.
- D . Neither the DBFS root nor mounted storage can be accessed when using %sh in a Databricks notebook.
- E . The DBFS root stores files in ephemeral block volumes attached to the driver, while mounted directories will always persist saved data to external storage between sessions.
A distributed team of data analysts share computing resources on an interactive cluster with autoscaling configured. In order to better manage costs and query throughput, the workspace administrator is hoping to evaluate whether cluster upscaling is caused by many concurrent users or resource-intensive queries.
In which location can one review the timeline for cluster resizing events?
- A . Workspace audit logs
- B . Driver’s log file
- C . Ganglia
- D . Cluster Event Log
- E . Executor’s log file
An upstream system is emitting change data capture (CDC) logs that are being written to a cloud object storage directory. Each record in the log indicates the change type (insert, update, or delete) and the values for each field after the change. The source table has a primary key identified by the field pk_id.
For auditing purposes, the data governance team wishes to maintain a full record of all values that have ever been valid in the source system. For analytical purposes, only the most recent value for each record needs to be recorded. The Databricks job to ingest these records occurs once per hour, but each individual record may have changed multiple times over the course of an hour.
Which solution meets these requirements?
- A . Create a separate history table for each pk_id resolve the current state of the table by running a union all filtering the history tables for the most recent state.
- B . Use merge into to insert, update, or delete the most recent entry for each pk_id into a bronze table, then propagate all changes throughout the system.
- C . Iterate through an ordered set of changes to the table, applying each in turn; rely on Delta Lake’s versioning ability to create an audit log.
- D . Use Delta Lake’s change data feed to automatically process CDC data from an external system, propagating all changes to all dependent tables in the Lakehouse.
- E . Ingest all log information into a bronze table; use merge into to insert, update, or delete the most recent entry for each pk_id into a silver table to recreate the current table state.
A data engineer is testing a collection of mathematical functions, one of which calculates the area under a curve as described by another function.
Which kind of the test does the above line exemplify?
- A . Integration
- B . Unit
- C . Manual
- D . functional
Which of the following is true of Delta Lake and the Lakehouse?
- A . Because Parquet compresses data row by row. strings will only be compressed when a character is repeated multiple times.
- B . Delta Lake automatically collects statistics on the first 32 columns of each table which are leveraged in data skipping based on query filters.
- C . Views in the Lakehouse maintain a valid cache of the most recent versions of source tables at all times.
- D . Primary and foreign key constraints can be leveraged to ensure duplicate values are never entered into a dimension table.
- E . Z-order can only be applied to numeric values stored in Delta Lake tables
A junior data engineer has configured a workload that posts the following JSON to the Databricks REST API endpoint 2.0/jobs/create.

Assuming that all configurations and referenced resources are available, which statement describes the result of executing this workload three times?
- A . Three new jobs named "Ingest new data" will be defined in the workspace, and they will each run once daily.
- B . The logic defined in the referenced notebook will be executed three times on new clusters with the configurations of the provided cluster ID.
- C . Three new jobs named "Ingest new data" will be defined in the workspace, but no jobs will be executed.
- D . One new job named "Ingest new data" will be defined in the workspace, but it will not be executed.
- E . The logic defined in the referenced notebook will be executed three times on the referenced existing all purpose cluster.
A data engineer wants to join a stream of advertisement impressions (when an ad was shown) with another stream of user clicks on advertisements to correlate when impression led to monitizable clicks.

Which solution would improve the performance?
A)
![]()
B)
![]()
C)
![]()
D)
![]()
- A . Option A
- B . Option B
- C . Option C
- D . Option D
An hourly batch job is configured to ingest data files from a cloud object storage container where each batch represent all records produced by the source system in a given hour. The batch job to process these records into the Lakehouse is sufficiently delayed to ensure no late-arriving data is missed.
The user_id field represents a unique key for the data, which has the following schema:
user_id BIGINT, username STRING, user_utc STRING, user_region STRING, last_login BIGINT, auto_pay BOOLEAN, last_updated BIGINT
New records are all ingested into a table named account_history which maintains a full record of all data in the same schema as the source. The next table in the system is named account_current and is implemented as a Type 1 table representing the most recent value for each unique user_id.
Assuming there are millions of user accounts and tens of thousands of records processed hourly, which implementation can be used to efficiently update the described account_current table as part of each hourly batch job?
- A . Use Auto Loader to subscribe to new files in the account history directory; configure a Structured Streaminq trigger once job to batch update newly detected files into the account current table.
- B . Overwrite the account current table with each batch using the results of a query against the account history table grouping by user id and filtering for the max value of last updated.
- C . Filter records in account history using the last updated field and the most recent hour processed, as well as the max last iogin by user id write a merge statement to update or insert the most recent
value for each user id. - D . Use Delta Lake version history to get the difference between the latest version of account history and one version prior, then write these records to account current.
- E . Filter records in account history using the last updated field and the most recent hour processed, making sure to deduplicate on username; write a merge statement to update or insert the most recent value for each username.
When scheduling Structured Streaming jobs for production, which configuration automatically recovers from query failures and keeps costs low?
- A . Cluster: New Job Cluster;
Retries: Unlimited;
Maximum Concurrent Runs: Unlimited - B . Cluster: New Job Cluster;
Retries: None;
Maximum Concurrent Runs: 1 - C . Cluster: Existing All-Purpose Cluster; Retries: Unlimited;
Maximum Concurrent Runs: 1 - D . Cluster: Existing All-Purpose Cluster; Retries: Unlimited;
Maximum Concurrent Runs: 1 - E . Cluster: Existing All-Purpose Cluster; Retries: None;
Maximum Concurrent Runs: 1