Databricks Databricks Generative AI Engineer Associate Übungsprüfungen
Zuletzt aktualisiert am 18.07.2026- Prüfungscode: Databricks Generative AI Engineer Associate
- Prüfungsname: Databricks Certified Generative AI Engineer Associate
- Zertifizierungsanbieter: Databricks
- Zuletzt aktualisiert am: 18.07.2026
A Generative Al Engineer is tasked with improving the RAG quality by addressing its inflammatory outputs.
Which action would be most effective in mitigating the problem of offensive text outputs?
- A . Increase the frequency of upstream data updates
- B . Inform the user of the expected RAG behavior
- C . Restrict access to the data sources to a limited number of users
- D . Curate upstream data properly that includes manual review before it is fed into the RAG system
A Generative AI Engineer developed an LLM application using the provisioned throughput Foundation Model API. Now that the application is ready to be deployed, they realize their volume of requests are not sufficiently high enough to create their own provisioned throughput endpoint. They want to choose a strategy that ensures the best cost-effectiveness for their application.
What strategy should the Generative AI Engineer use?
- A . Switch to using External Models instead
- B . Deploy the model using pay-per-token throughput as it comes with cost guarantees
- C . Change to a model with a fewer number of parameters in order to reduce hardware constraint issues
- D . Throttle the incoming batch of requests manually to avoid rate limiting issues
A Generative Al Engineer is responsible for developing a chatbot to enable their company’s internal HelpDesk Call Center team to more quickly find related tickets and provide resolution. While creating the GenAI application work breakdown tasks for this project, they realize they need to start planning which data sources (either Unity Catalog volume or Delta table) they could choose for this application.
They have collected several candidate data sources for consideration:
call_rep_history: a Delta table with primary keys representative_id, call_id. This table is maintained to calculate representatives’ call resolution from fields call_duration and call start_time.
transcript Volume: a Unity Catalog Volume of all recordings as a *.wav files, but also a text transcript as *.txt files.
call_cust_history: a Delta table with primary keys customer_id, cal1_id. This table is maintained to calculate how much internal customers use the HelpDesk to make sure that the charge back model is consistent with actual service use.
call_detail: a Delta table that includes a snapshot of all call details updated hourly. It includes root_cause and resolution fields, but those fields may be empty for calls that are still active.
maintenance_schedule C a Delta table that includes a listing of both HelpDesk application outages as well as planned upcoming maintenance downtimes.
They need sources that could add context to best identify ticket root cause and resolution.
Which TWO sources do that? (Choose two.)
- A . call_cust_history
- B . maintenance_schedule
- C . call_rep_history
- D . call_detail
- E . transcript Volume
A team wants to serve a code generation model as an assistant for their software developers. It should support multiple programming languages. Quality is the primary objective.
Which of the Databricks Foundation Model APIs, or models available in the Marketplace, would be the best fit?
- A . Llama2-70b
- B . BGE-large
- C . MPT-7b
- D . CodeLlama-34B
A company has a typical RAG-enabled, customer-facing chatbot on its website.
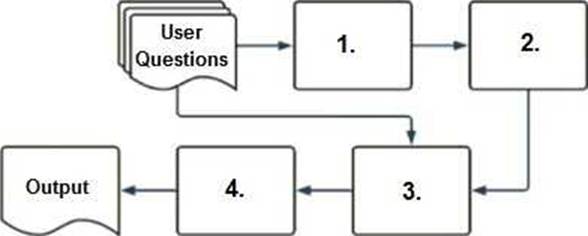
Select the correct sequence of components a user’s questions will go through before the final output is returned. Use the diagram above for reference.
- A . 1. embedding model, 2. vector search, 3. context-augmented prompt, 4. response-generating LLM
- B . 1. context-augmented prompt, 2. vector search, 3. embedding model, 4. response-generating LLM
- C . 1. response-generating LLM, 2. vector search, 3. context-augmented prompt, 4. embedding model
- D . 1. response-generating LLM, 2. context-augmented prompt, 3. vector search, 4. embedding model
When developing an LLM application, it’s crucial to ensure that the data used for training the model complies with licensing requirements to avoid legal risks.
Which action is NOT appropriate to avoid legal risks?
- A . Reach out to the data curators directly before you have started using the trained model to let them know.
- B . Use any available data you personally created which is completely original and you can decide what license to use.
- C . Only use data explicitly labeled with an open license and ensure the license terms are followed.
- D . Reach out to the data curators directly after you have started using the trained model to let them know.
A Generative AI Engineer I using the code below to test setting up a vector store:

Assuming they intend to use Databricks managed embeddings with the default embedding model, what should be the next logical function call?
- A . vsc.get_index()
- B . vsc.create_delta_sync_index()
- C . vsc.create_direct_access_index()
- D . vsc.similarity_search()
A Generative AI Engineer is designing a chatbot for a gaming company that aims to engage users on its platform while its users play online video games.
Which metric would help them increase user engagement and retention for their platform?
- A . Randomness
- B . Diversity of responses
- C . Lack of relevance
- D . Repetition of responses
A Generative Al Engineer would like an LLM to generate formatted JSON from emails. This will require parsing and extracting the following information: order ID, date, and sender email.
Here’s a sample email:
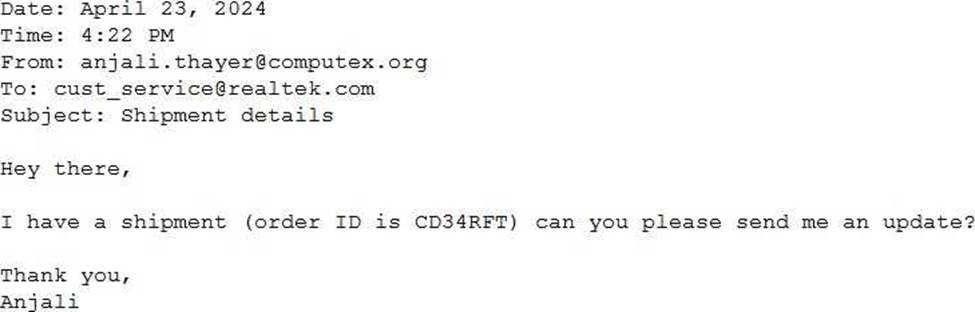
They will need to write a prompt that will extract the relevant information in JSON format with the highest level of output accuracy.
Which prompt will do that?
- A . You will receive customer emails and need to extract date, sender email, and order ID. You should return the date, sender email, and order ID information in JSON format.
- B . You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
Here’s an example: {“date”: “April 16, 2024”, “sender_email”: “[email protected]”, “order_id”: “RE987D”} - C . You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in a human-readable format.
- D . You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
Which indicator should be considered to evaluate the safety of the LLM outputs when qualitatively assessing LLM responses for a translation use case?
- A . The ability to generate responses in code
- B . The similarity to the previous language
- C . The latency of the response and the length of text generated
- D . The accuracy and relevance of the responses