Databricks Databricks Generative AI Engineer Associate Übungsprüfungen
Zuletzt aktualisiert am 26.04.2025- Prüfungscode: Databricks Generative AI Engineer Associate
- Prüfungsname: Databricks Certified Generative AI Engineer Associate
- Zertifizierungsanbieter: Databricks
- Zuletzt aktualisiert am: 26.04.2025
A Generative AI Engineer is designing an LLM-powered live sports commentary platform. The platform provides real-time updates and LLM-generated analyses for any users who would like to have live summaries, rather than reading a series of potentially outdated news articles.
Which tool below will give the platform access to real-time data for generating game analyses based on the latest game scores?
- A . DatabrickslQ
- B . Foundation Model APIs
- C . Feature Serving
- D . AutoML
A Generative AI Engineer is developing an LLM application that users can use to generate personalized birthday poems based on their names.
Which technique would be most effective in safeguarding the application, given the potential for malicious user inputs?
- A . Implement a safety filter that detects any harmful inputs and ask the LLM to respond that it is unable to assist
- B . Reduce the time that the users can interact with the LLM
- C . Ask the LLM to remind the user that the input is malicious but continue the conversation with the user
- D . Increase the amount of compute that powers the LLM to process input faster
A Generative Al Engineer has already trained an LLM on Databricks and it is now ready to be deployed.
Which of the following steps correctly outlines the easiest process for deploying a model on Databricks?
- A . Log the model as a pickle object, upload the object to Unity Catalog Volume, register it to Unity Catalog using MLflow, and start a serving endpoint
- B . Log the model using MLflow during training, directly register the model to Unity Catalog using the MLflow API, and start a serving endpoint
- C . Save the model along with its dependencies in a local directory, build the Docker image, and run the Docker container
- D . Wrap the LLM’s prediction function into a Flask application and serve using Gunicorn
A small and cost-conscious startup in the cancer research field wants to build a RAG application using Foundation Model APIs.
Which strategy would allow the startup to build a good-quality RAG application while being cost-conscious and able to cater to customer needs?
- A . Limit the number of relevant documents available for the RAG application to retrieve from
- B . Pick a smaller LLM that is domain-specific
- C . Limit the number of queries a customer can send per day
- D . Use the largest LLM possible because that gives the best performance for any general queries
A Generative AI Engineer has been asked to build an LLM-based question-answering application. The application should take into account new documents that are frequently published. The engineer wants to build this application with the least cost and least development effort and have it operate at the lowest cost possible.
Which combination of chaining components and configuration meets these requirements?
- A . For the application a prompt, a retriever, and an LLM are required. The retriever output is inserted into the prompt which is given to the LLM to generate answers.
- B . The LLM needs to be frequently with the new documents in order to provide most up-to-date answers.
- C . For the question-answering application, prompt engineering and an LLM are required to generate answers.
- D . For the application a prompt, an agent and a fine-tuned LLM are required. The agent is used by the LLM to retrieve relevant content that is inserted into the prompt which is given to the LLM to generate answers.
A Generative Al Engineer has developed an LLM application to answer questions about internal company policies. The Generative AI Engineer must ensure that the application doesn’t hallucinate or leak confidential data.
Which approach should NOT be used to mitigate hallucination or confidential data leakage?
- A . Add guardrails to filter outputs from the LLM before it is shown to the user
- B . Fine-tune the model on your data, hoping it will learn what is appropriate and not
- C . Limit the data available based on the user’s access level
- D . Use a strong system prompt to ensure the model aligns with your needs.
After changing the response generating LLM in a RAG pipeline from GPT-4 to a model with a shorter context length that the company self-hosts, the Generative AI Engineer is getting the following error:
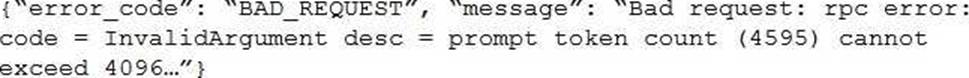
What TWO solutions should the Generative AI Engineer implement without changing the response generating model? (Choose two.)
- A . Use a smaller embedding model to generate
- B . Reduce the maximum output tokens of the new model
- C . Decrease the chunk size of embedded documents
- D . Reduce the number of records retrieved from the vector database
- E . Retrain the response generating model using ALiBi
A Generative AI Engineer is building an LLM to generate article summaries in the form of a type of poem, such as a haiku, given the article content. However, the initial output from the LLM does not match the desired tone or style.
Which approach will NOT improve the LLM’s response to achieve the desired response?
- A . Provide the LLM with a prompt that explicitly instructs it to generate text in the desired tone and style
- B . Use a neutralizer to normalize the tone and style of the underlying documents
- C . Include few-shot examples in the prompt to the LLM
- D . Fine-tune the LLM on a dataset of desired tone and style