Microsoft DP-203 Übungsprüfungen
Zuletzt aktualisiert am 26.04.2025- Prüfungscode: DP-203
- Prüfungsname: Data Engineering on Microsoft Azure
- Zertifizierungsanbieter: Microsoft
- Zuletzt aktualisiert am: 26.04.2025
HOTSPOT
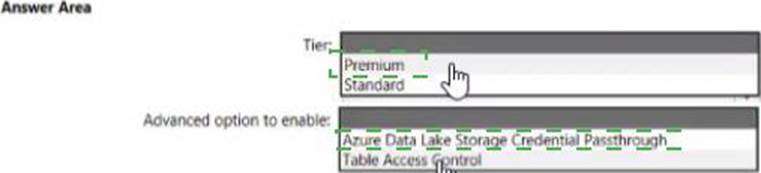
You need to implement an Azure Databricks cluster that automatically connects to Azure Data lake Storage Gen2 by using Azure Active Directory (Azure AD) integration.
How should you configure the new clutter? To answer, select the appropriate options in the answers area. NOTE: Each correct selection is worth one point.

You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1.
You have files that are ingested and loaded into an Azure Data Lake Storage Gen2 container named container1.
You plan to insert data from the files into Table1 and azure Data Lake Storage Gen2 container named container1.
You plan to insert data from the files into Table1 and transform the data. Each row of data in the files will produce one row in the serving layer of Table1.
You need to ensure that when the source data files are loaded to container1, the DateTime is stored as an additional column in Table1.
Solution: In an Azure Synapse Analytics pipeline, you use a data flow that contains a Derived Column transformation.
- A . Yes
- B . No
You have an Azure Synapse Analytics dedicated SQL pool that contains a large fact table. The table contains 50 columns and 5 billion rows and is a heap.
Most queries against the table aggregate values from approximately 100 million rows and return only two columns.
You discover that the queries against the fact table are very slow.
Which type of index should you add to provide the fastest query times?
- A . nonclustered columnstore
- B . clustered columnstore
- C . nonclustered
- D . clustered
You have files and folders in Azure Data Lake Storage Gen2 for an Azure Synapse workspace as shown in the following exhibit.
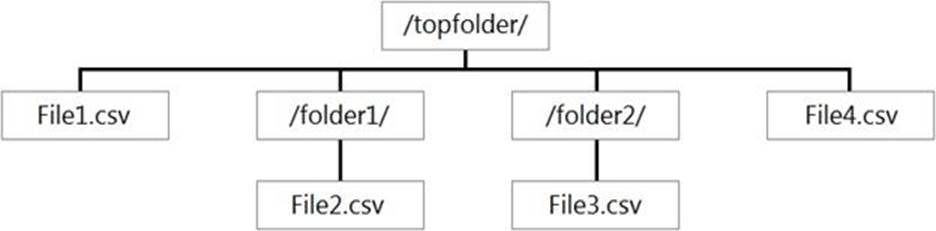
You create an external table named ExtTable that has LOCATION=’/topfolder/‘.
When you query ExtTable by using an Azure Synapse Analytics serverless SQL pool, which files are returned?
- A . File2.csv and File3.csv only
- B . File1.csv and File4.csv only
- C . File1.csv, File2.csv, File3.csv, and File4.csv
- D . File1.csv only
You have a table in an Azure Synapse Analytics dedicated SQL pool.
The table was created by using the following Transact-SQL statement.

You need to alter the table to meet the following requirements:
✑ Ensure that users can identify the current manager of employees.
✑ Support creating an employee reporting hierarchy for your entire company.
✑ Provide fast lookup of the managers’ attributes such as name and job title.
Which column should you add to the table?
- A . [ManagerEmployeeID] [int] NULL
- B . [ManagerEmployeeID] [smallint] NULL
- C . [ManagerEmployeeKey] [int] NULL
- D . [ManagerName] [varchar](200) NULL
HOTSPOT
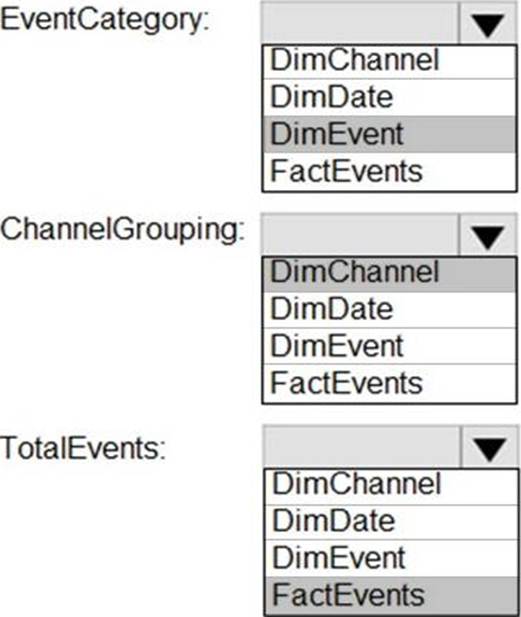
From a website analytics system, you receive data extracts about user interactions such as downloads, link clicks, form submissions, and video plays.
The data contains the following columns.
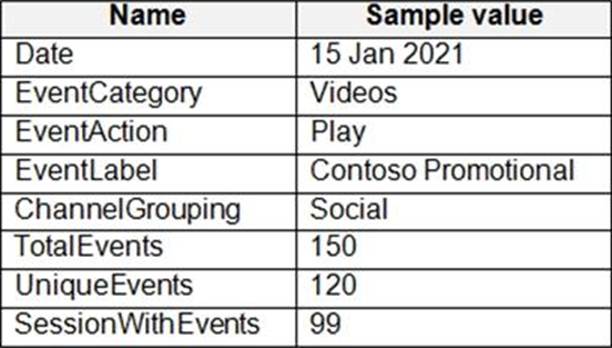
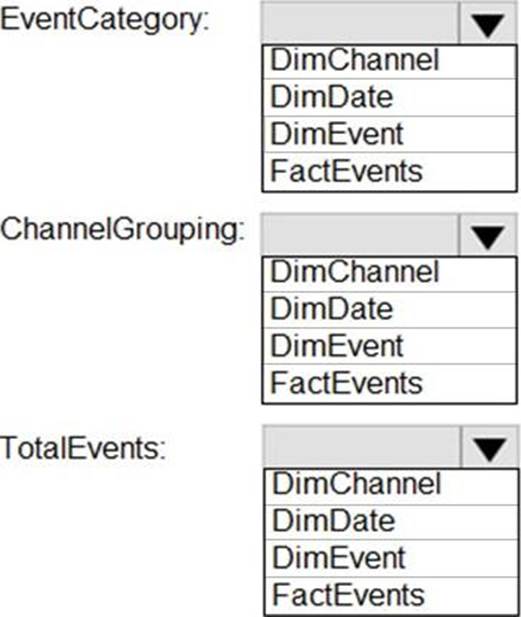
You need to design a star schema to support analytical queries of the data. The star schema will contain four tables including a date dimension.
To which table should you add each column? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You have an Azure Stream Analytics job.
You need to ensure that the job has enough streaming units provisioned.
You configure monitoring of the SU % Utilization metric.
Which two additional metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Backlogged Input Events
- B . Watermark Delay
- C . Function Events
- D . Out of order Events
- E . Late Input Events
You need to design a data retention solution for the Twitter teed data records. The solution must meet the customer sentiment analytics requirements.
Which Azure Storage functionality should you include in the solution?
- A . time-based retention
- B . change feed
- C . soft delete
- D . Iifecycle management
You need to schedule an Azure Data Factory pipeline to execute when a new file arrives in an Azure Data Lake Storage Gen2 container.
Which type of trigger should you use?
- A . on-demand
- B . tumbling window
- C . schedule
- D . storage event
You have an Azure Synapse Analytics dedicated SQL pool mat contains a table named dbo.Users. You need to prevent a group of users from reading user email addresses from dbo.Users.
What should you use?
- A . row-level security
- B . column-level security
- C . Dynamic data masking
- D . Transparent Data Encryption (TDD