Microsoft DP-203 Übungsprüfungen
Zuletzt aktualisiert am 27.04.2025- Prüfungscode: DP-203
- Prüfungsname: Data Engineering on Microsoft Azure
- Zertifizierungsanbieter: Microsoft
- Zuletzt aktualisiert am: 27.04.2025
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and a database named DB1.
DB1 contains a fact table named Table1.
You need to identify the extent of the data skew in Table1.
What should you do in Synapse Studio?
- A . Connect to the built-in pool and run dbcc pdw_showspaceused.
- B . Connect to the built-in pool and run dbcc checkalloc.
- C . Connect to Pool1 and query sys.dm_pdw_node_scacus.
- D . Connect to Pool1 and query sys.dm_pdw_nodes_db_partition_scacs.
HOTSPOT
You have a data model that you plan to implement in a data warehouse in Azure Synapse Analytics as shown in the following exhibit.
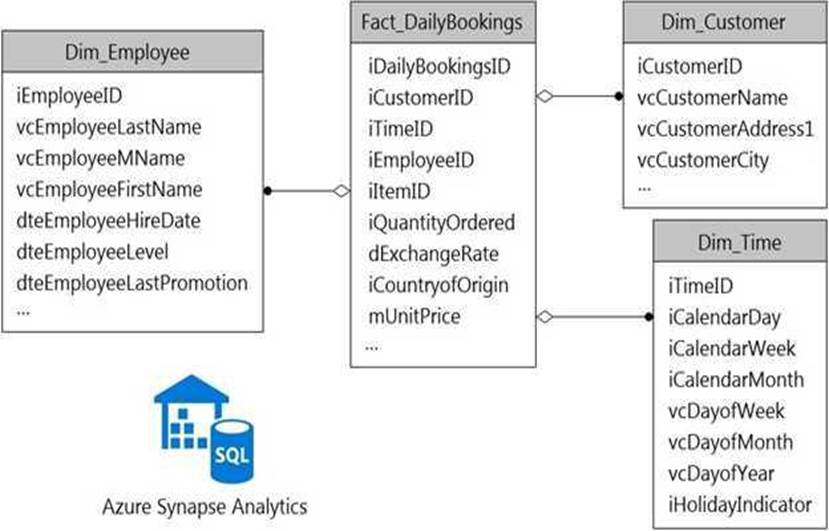
All the dimension tables will be less than 2 GB after compression, and the fact table will be approximately 6 TB.
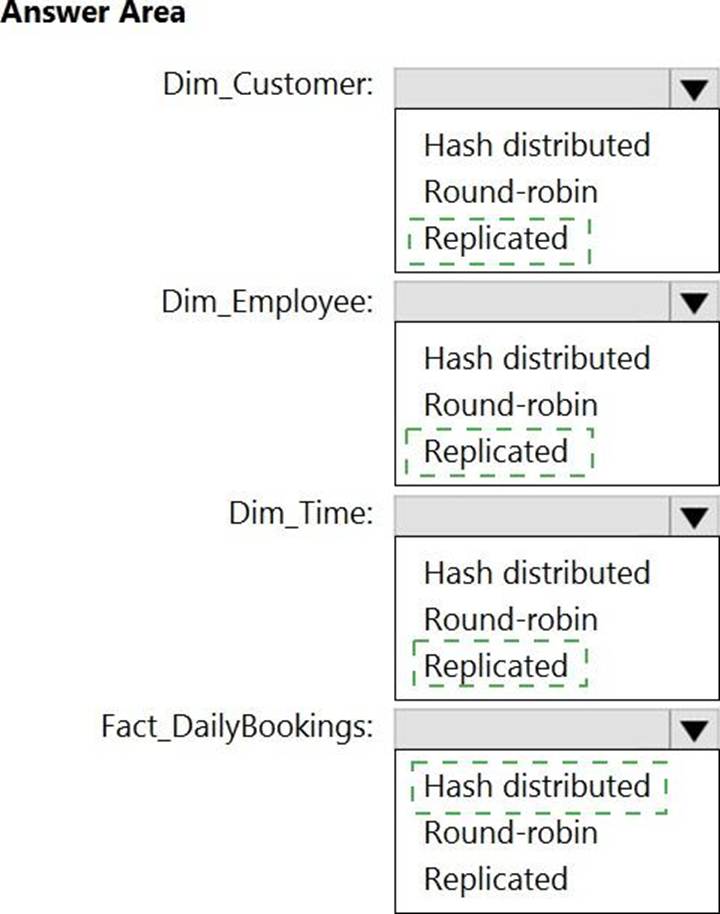
Which type of table should you use for each table? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
HOTSPOT
You have an Azure Synapse Analytics workspace that contains three pipelines and three triggers named Trigger 1. Trigger2, and Tiigger3.
Trigger 3 has the following definition.



You use Azure Stream Analytics to receive Twitter data from Azure Event Hubs and to output the data to an Azure Blob storage account.
You need to output the count of tweets during the last five minutes every five minutes. Each tweet must only be counted once.
Which windowing function should you use?
- A . a five-minute Session window
- B . a five-minute Sliding window
- C . a five-minute Tumbling window
- D . a five-minute Hopping window that has one-minute hop
You have an Azure data factory named ADM.
You currently publish all pipeline authoring changes directly to ADF1.
You need to implement version control for the changes made to pipeline artifacts The solution must ensure that you can apply version control to the resources currently defined in the Azure Data Factory Studio for AOFl
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Create an Azure Data Factory trigger.
- B . From the Azure Data Factory Studio, select Publish.
- C . From the Azure Data Factory Studio, run Publish All
- D . Create a Git repository.
- E . Create a GitHub action.
- F . From the Azure Data Factory Studio, select up code respository
HOTSPOT
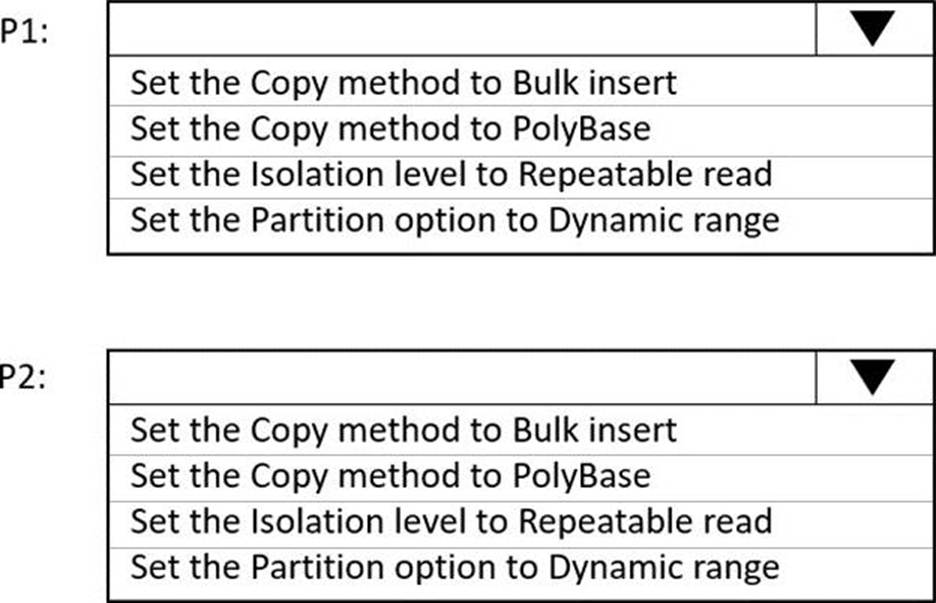
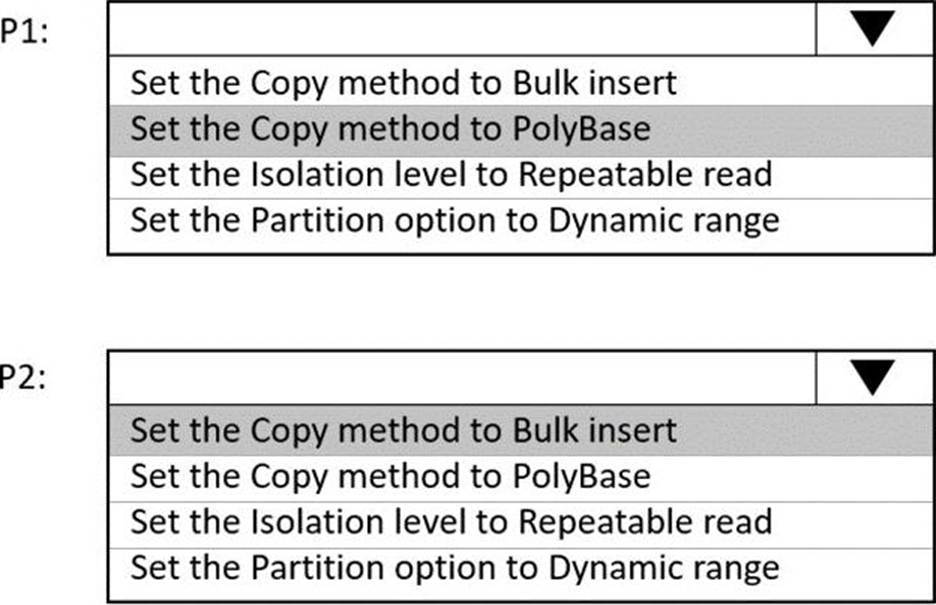
You have an Azure Data Factory instance named ADF1 and two Azure Synapse Analytics workspaces named WS1 and WS2.
ADF1 contains the following pipelines:
✑ P1: Uses a copy activity to copy data from a nonpartitioned table in a dedicated SQL pool of WS1 to an Azure Data Lake Storage Gen2 account
✑ P2: Uses a copy activity to copy data from text-delimited files in an Azure Data Lake Storage Gen2 account to a nonpartitioned table in a dedicated SQL pool of WS2
You need to configure P1 and P2 to maximize parallelism and performance.
Which dataset settings should you configure for the copy activity if each pipeline? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You have an Azure Synapse Analytics dedicated SQL pool named Pool1.
Pool! contains two tables named SalesFact_Stagmg and SalesFact. Both tables have a matching number of partitions, all of which contain data.
You need to load data from SalesFact_Staging to SalesFact by switching a partition.
What should you specify when running the alter TABLE statement?
- A . WITH NOCHECK
- B . WITH (TRUNCATE.TASGET = ON)
- C . WITH (TRACK.COLUMNS. UPOATED =ON)
- D . WITH CHECK
You need to trigger an Azure Data Factory pipeline when a file arrives in an Azure Data Lake Storage Gen2 container.
Which resource provider should you enable?
- A . Microsoft.Sql
- B . Microsoft-Automation
- C . Microsoft.EventGrid
- D . Microsoft.EventHub
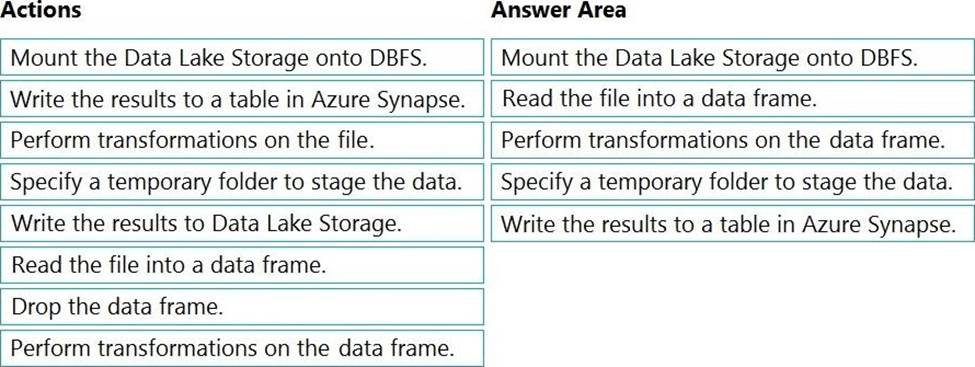
DRAG DROP
You have an Azure Data Lake Storage Gen2 account that contains a JSON file for customers. The file contains two attributes named FirstName and LastName.
You need to copy the data from the JSON file to an Azure Synapse Analytics table by using Azure Databricks. A new column must be created that concatenates the FirstName and LastName values.
You create the following components:
✑ A destination table in Azure Synapse
✑ An Azure Blob storage container
✑ A service principal
Which five actions should you perform in sequence next in is Databricks notebook? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

HOTSPOT
You have an Azure data factory that is configured to use a Git repository for source control as shown in the following exhibit.
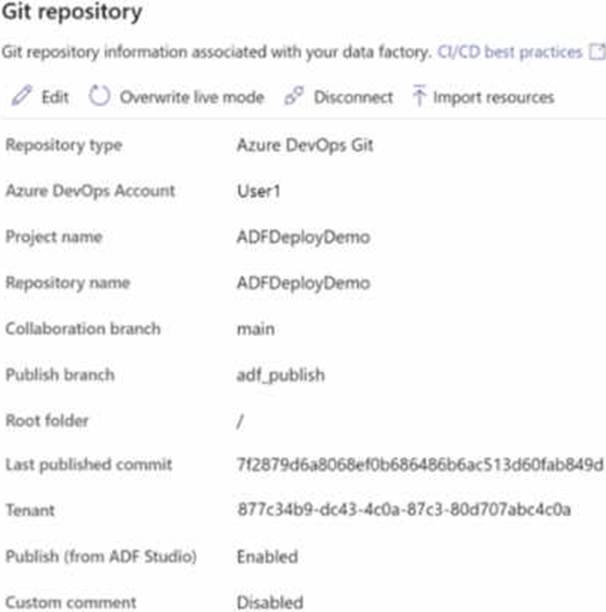
Use the drop-down menus to select the answer choice that completes each statement based upon the information presented in the graphic. NOTE: Each correct selection is worth one point.

