Microsoft DP-203 Übungsprüfungen
Zuletzt aktualisiert am 27.04.2025- Prüfungscode: DP-203
- Prüfungsname: Data Engineering on Microsoft Azure
- Zertifizierungsanbieter: Microsoft
- Zuletzt aktualisiert am: 27.04.2025
You plan to implement an Azure Data Lake Gen2 storage account.
You need to ensure that the data lake will remain available if a data center fails in the primary Azure region.
The solution must minimize costs.
Which type of replication should you use for the storage account?
- A . geo-redundant storage (GRS)
- B . zone-redundant storage (ZRS)
- C . locally-redundant storage (LRS)
- D . geo-zone-redundant storage (GZRS)
You have an Azure subscription that contains a Microsoft Purview account named MP1, an Azure data factory named DF1, and a storage account named storage. MP1 is configured 10 scan storage1. DF1 is connected to MP1 and contains 3 dataset named DS1. DS1 references 2 file in storage.
In DF1, you plan to create a pipeline that will process data from DS1.
You need to review the schema and lineage information in MP1 for the data referenced by DS1.
Which two features can you use to locate the information? Each correct answer presents a complete solution. NOTE: Each correct answer is worth one point.
- A . the Storage browser of storage1 in the Azure portal
- B . the search bar in the Azure portal
- C . the search bar in Azure Data Factory Studio
- D . the search bar in the Microsoft Purview governance portal
DRAG DROP
You have data stored in thousands of CSV files in Azure Data Lake Storage Gen2. Each file has a header row followed by a properly formatted carriage return (/r) and line feed (/n).
You are implementing a pattern that batch loads the files daily into an enterprise data warehouse in Azure Synapse Analytics by using PolyBase.
You need to skip the header row when you import the files into the data warehouse. Before building the loading pattern, you need to prepare the required database objects in Azure Synapse Analytics.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: Each correct selection is worth one point


DRAG DROP
You have data stored in thousands of CSV files in Azure Data Lake Storage Gen2. Each file has a header row followed by a properly formatted carriage return (/r) and line feed (/n).
You are implementing a pattern that batch loads the files daily into an enterprise data warehouse in Azure Synapse Analytics by using PolyBase.
You need to skip the header row when you import the files into the data warehouse. Before building the loading pattern, you need to prepare the required database objects in Azure Synapse Analytics.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: Each correct selection is worth one point
You have an Azure Factory instance named DF1 that contains a pipeline named PL1.PL1 includes a tumbling window trigger.
You create five clones of PL1. You configure each clone pipeline to use a different data source.
You need to ensure that the execution schedules of the clone pipeline match the execution schedule of PL1.
What should you do?
- A . Add a new trigger to each cloned pipeline
- B . Associate each cloned pipeline to an existing trigger.
- C . Create a tumbling window trigger dependency for the trigger of PL1.
- D . Modify the Concurrency setting of each pipeline.
You have an Azure data factory that connects to a Microsoft Purview account. The data ‚factory is
registered in Microsoft Purview.
You update a Data Factory pipeline.
You need to ensure that the updated lineage is available in Microsoft Purview.
What should you do first?
- A . Disconnect the Microsoft Purview account from the data factory.
- B . Locate the related asset in the Microsoft Purview portal.
- C . Execute an Azure DevOps build pipeline.
- D . Execute the pipeline.
HOTSPOT
You have an Azure subscription that contains an Azure Data Lake Storage account. The storage account contains a data lake named DataLake1.
You plan to use an Azure data factory to ingest data from a folder in DataLake1, transform the data, and land the data in another folder.
You need to ensure that the data factory can read and write data from any folder in the DataLake1 file system.
The solution must meet the following requirements:
✑ Minimize the risk of unauthorized user access.
✑ Use the principle of least privilege.
✑ Minimize maintenance effort.
How should you configure access to the storage account for the data factory? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have an Azure Data Lake Storage Gen2 account named adls2 that is protected by a virtual network.
You are designing a SQL pool in Azure Synapse that will use adls2 as a source.
What should you use to authenticate to adls2?
- A . a shared access signature (SAS)
- B . a managed identity
- C . a shared key
- D . an Azure Active Directory (Azure AD) user
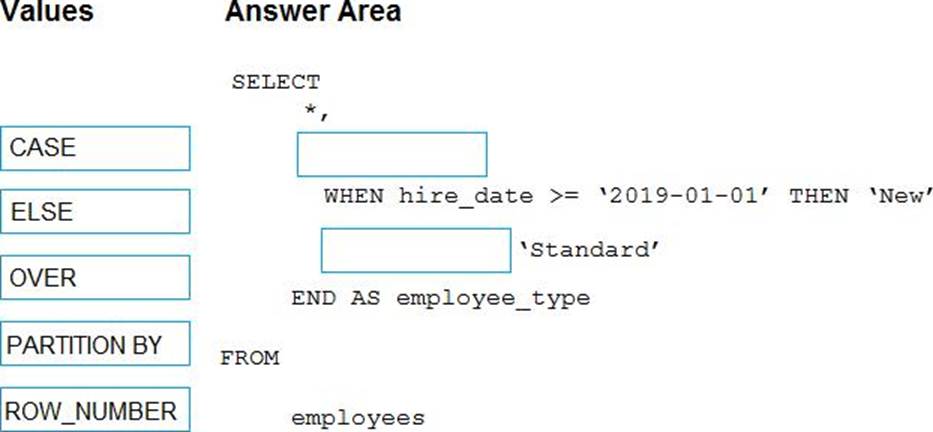
DRAG DROP
You have the following table named Employees.

You need to calculate the employee_type value based on the hire_date value.
How should you complete the Transact-SQL statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.

You are designing an anomaly detection solution for streaming data from an Azure IoT hub.
The solution must meet the following requirements:
✑ Send the output to Azure Synapse.
✑ Identify spikes and dips in time series data.
✑ Minimize development and configuration effort.
Which should you include in the solution?
- A . Azure Databricks
- B . Azure Stream Analytics
- C . Azure SQL Database