Microsoft DP-203 Übungsprüfungen
Zuletzt aktualisiert am 27.04.2025- Prüfungscode: DP-203
- Prüfungsname: Data Engineering on Microsoft Azure
- Zertifizierungsanbieter: Microsoft
- Zuletzt aktualisiert am: 27.04.2025
HOTSPOT
You have an Azure SQL database named Database1 and two Azure event hubs named HubA and HubB.
The data consumed from each source is shown in the following table.
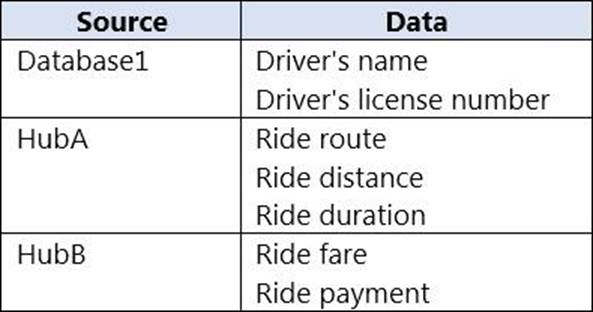
You need to implement Azure Stream Analytics to calculate the average fare per mile by driver.
How should you configure the Stream Analytics input for each source? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

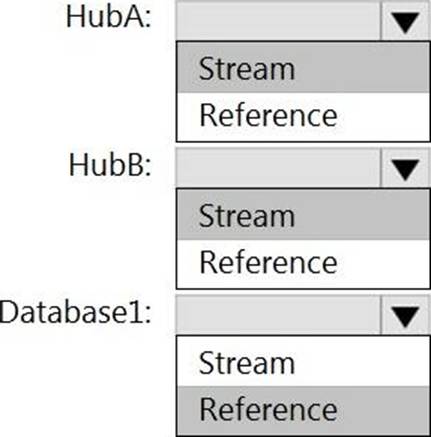
You have two fact tables named Flight and Weather. Queries targeting the tables will be based on the join between the following columns.
You need to recommend a solution that maximum query performance.
What should you include in the recommendation?
- A . In each table, create a column as a composite of the other two columns in the table.
- B . In each table, create an IDENTITY column.
- C . In the tables, use a hash distribution of ArriveDateTime and ReportDateTime.
- D . In the tables, use a hash distribution of ArriveAirPortID and AirportID.
You are designing an Azure Data Lake Storage solution that will transform raw JSON files for use in an analytical workload.
You need to recommend a format for the transformed files.
The solution must meet the following requirements:
✑ Contain information about the data types of each column in the files.
✑ Support querying a subset of columns in the files.
✑ Support read-heavy analytical workloads.
✑ Minimize the file size.
What should you recommend?
- A . JSON
- B . CSV
- C . Apache Avro
- D . Apache Parquet
You have two Azure Blob Storage accounts named account1 and account2?
You plan to create an Azure Data Factory pipeline that will use scheduled intervals to replicate newly created or modified blobs from account1 to account?
You need to recommend a solution to implement the pipeline.
The solution must meet the following requirements:
• Ensure that the pipeline only copies blobs that were created of modified since the most recent replication event.
• Minimize the effort to create the pipeline.
What should you recommend?
- A . Create a pipeline that contains a flowlet.
- B . Create a pipeline that contains a Data Flow activity.
- C . Run the Copy Data tool and select Metadata-driven copy task.
- D . Run the Copy Data tool and select Built-in copy task.
HOTSPOT
You have an Azure data factory that has the Git repository settings shown in the following exhibit.
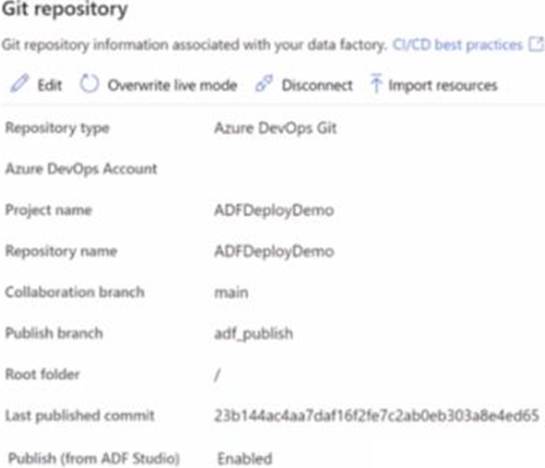
Use the drop-down menus to select the answer choose that completes each statement based on the information presented in the graphic. NOTE: Each correct answer is worth one point.


HOTSPOT
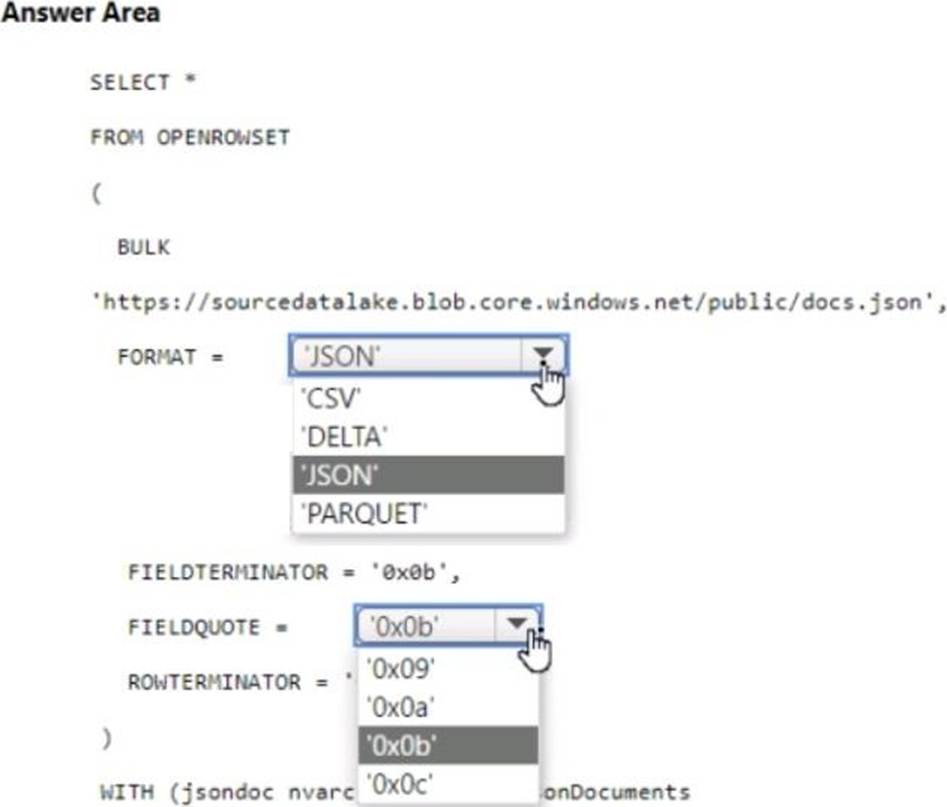
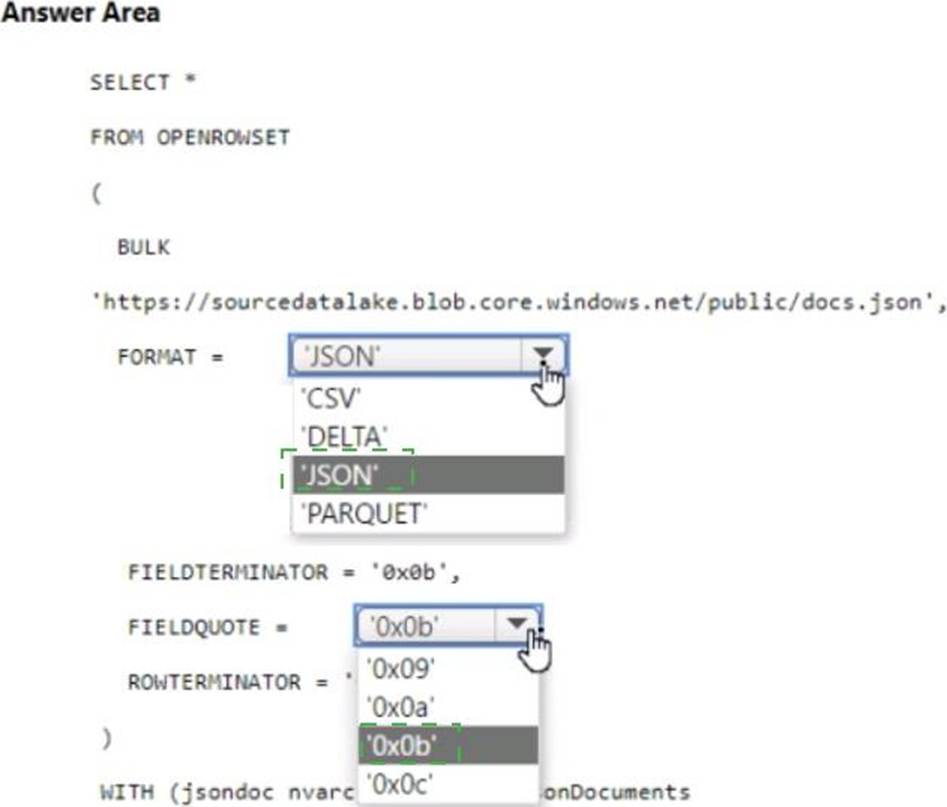
You have an Azure Synapse serverless SQL pool.
You need to read JSON documents from a file by using the OPENROWSET function.
How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You are designing an Azure Synapse Analytics dedicated SQL pool.
You need to ensure that you can audit access to Personally Identifiable information (PII).
What should you include in the solution?
- A . dynamic data masking
- B . row-level security (RLS)
- C . sensitivity classifications
- D . column-level security
You have an Azure Synapse Analytics serverless SQL pool named Pool1 and an Azure Data Lake Storage Gen2 account named storage1. The AllowedBlobpublicAccess porperty is disabled for storage1.
You need to create an external data source that can be used by Azure Active Directory (Azure AD)
users to access storage1 from Pool1.
What should you create first?
- A . an external resource pool
- B . a remote service binding
- C . database scoped credentials
- D . an external library
You have an Azure Synapse Analytics Apache Spark pool named Pool1.
You plan to load JSON files from an Azure Data Lake Storage Gen2 container into the tables in Pool1.
The structure and data types vary by file.
You need to load the files into the tables. The solution must maintain the source data types.
What should you do?
- A . Use a Get Metadata activity in Azure Data Factory.
- B . Use a Conditional Split transformation in an Azure Synapse data flow.
- C . Load the data by using the OPEHROwset Transact-SQL command in an Azure Synapse Anarytics serverless SQL pool.
- D . Load the data by using PySpark.
HOTSPOT
You have an Azure subscription that contains a logical Microsoft SQL server named Server1. Server1 hosts an Azure Synapse Analytics SQL dedicated pool named Pool1.
You need to recommend a Transparent Data Encryption (TDE) solution for Server1.
The solution must meet the following requirements:
✑ Track the usage of encryption keys.
✑ Maintain the access of client apps to Pool1 in the event of an Azure datacenter outage that affects the availability of the encryption keys.
What should you include in the recommendation? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

