Microsoft DP-203 Übungsprüfungen
Zuletzt aktualisiert am 07.07.2025- Prüfungscode: DP-203
- Prüfungsname: Data Engineering on Microsoft Azure
- Zertifizierungsanbieter: Microsoft
- Zuletzt aktualisiert am: 07.07.2025
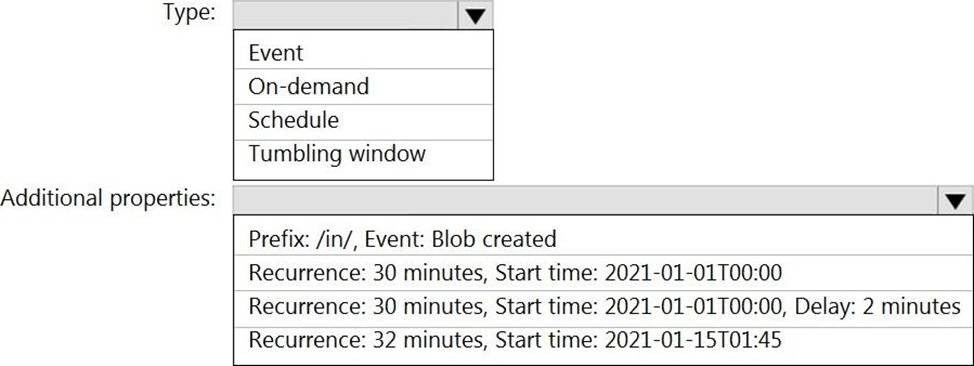
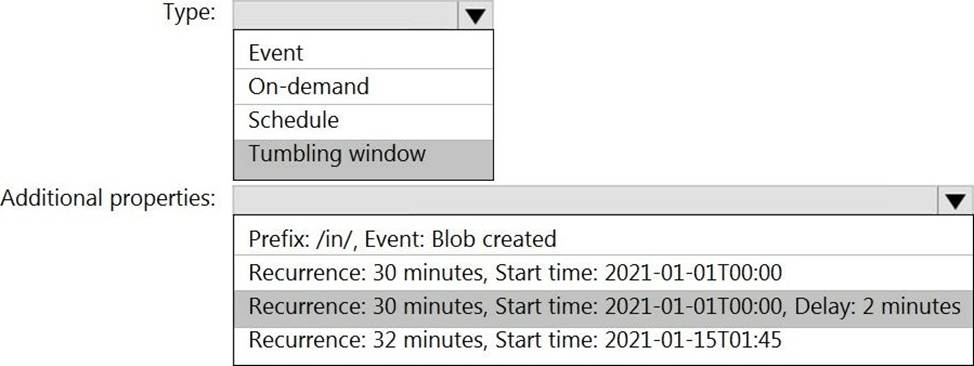
HOTSPOT
You build an Azure Data Factory pipeline to move data from an Azure Data Lake Storage Gen2 container to a database in an Azure Synapse Analytics dedicated SQL pool.
Data in the container is stored in the following folder structure.
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
The earliest folder is /in/2021/01/01/00/00. The latest folder is /in/2021/01/15/01/45.
You need to configure a pipeline trigger to meet the following requirements:
✑ Existing data must be loaded.
✑ Data must be loaded every 30 minutes.
✑ Late-arriving data of up to two minutes must he included in the load for the time at which the data should have arrived.
How should you configure the pipeline trigger? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
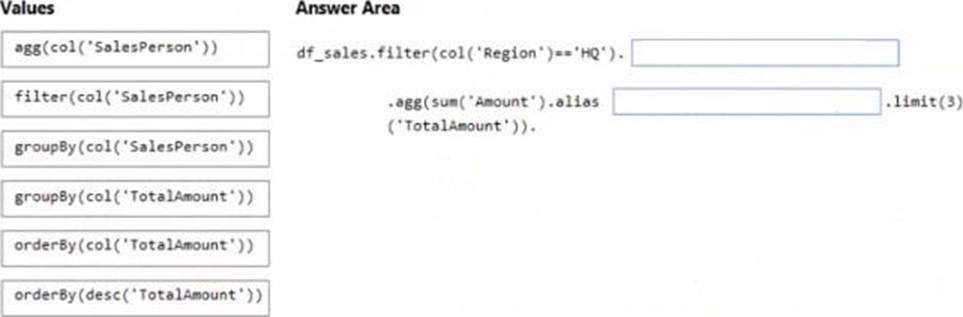
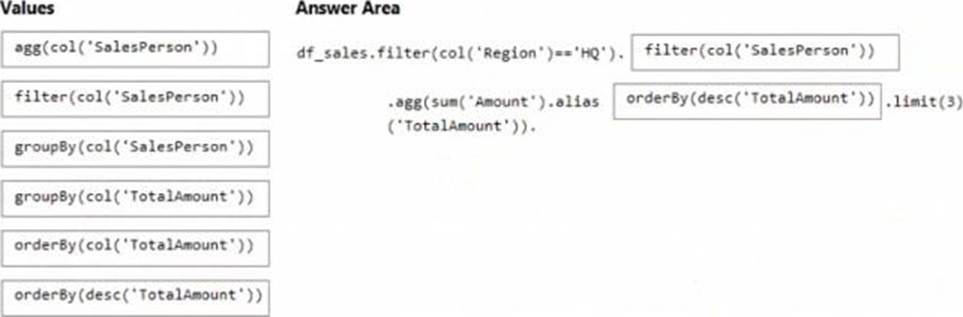
DRAG DROP
You have an Azure subscription that contains an Azure Databricks workspace. The workspace contains a notebook named Notebook1.
In Notebook1, you create an Apache Spark DataFrame named df_sales that contains the following columns:
• Customer
• Salesperson
• Region
• Amount
You need to identify the three top performing salespersons by amount for a region named HQ.
How should you complete the query? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
HOTSPOT
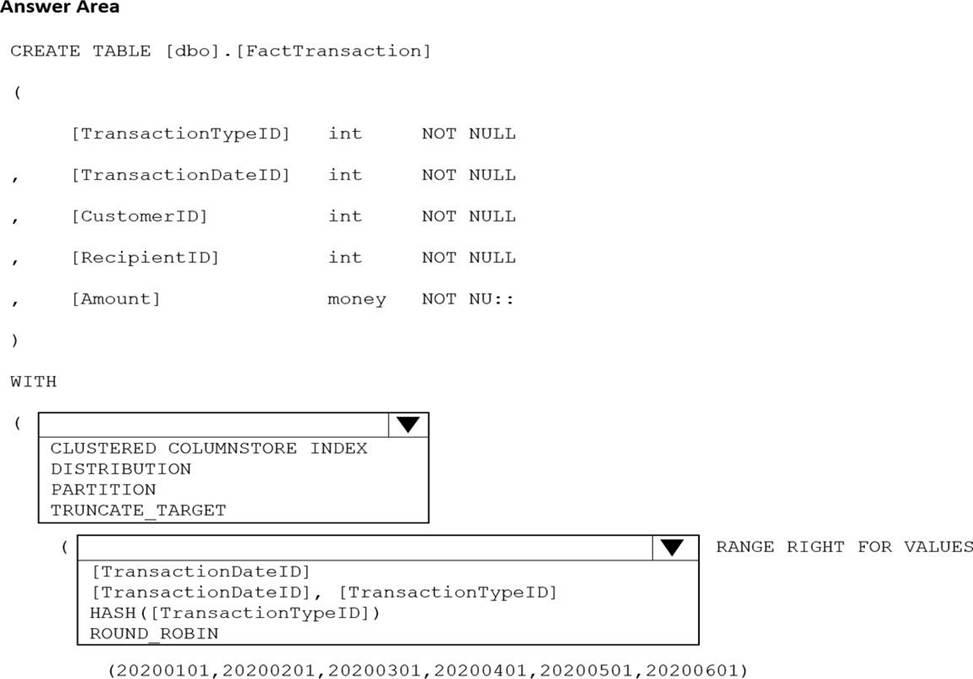
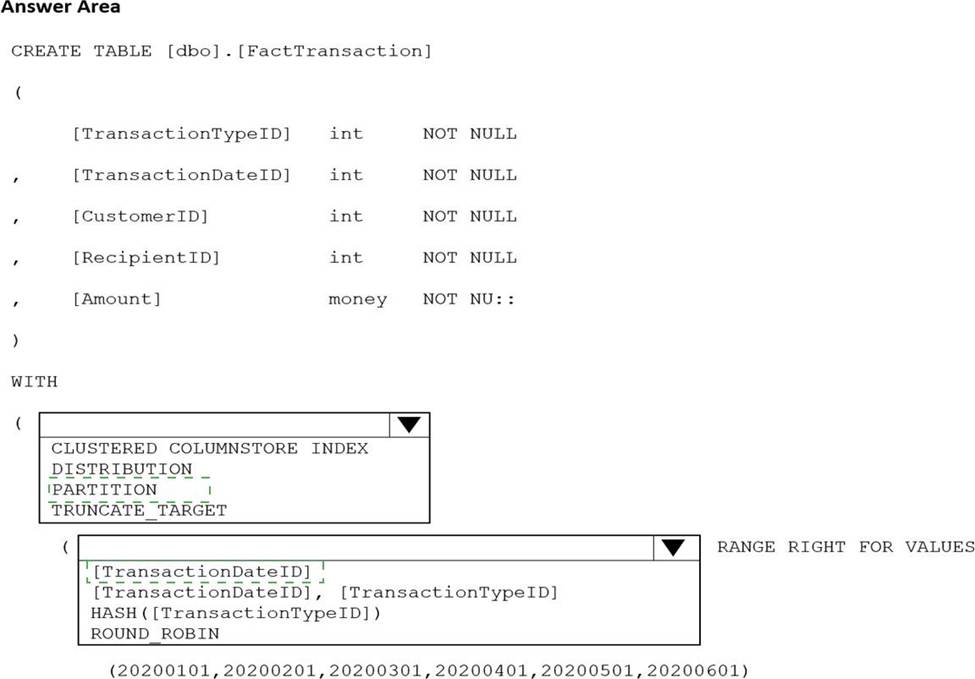
You are building an Azure Synapse Analytics dedicated SQL pool that will contain a fact table for transactions from the first half of the year 2020.
You need to ensure that the table meets the following requirements:
Minimizes the processing time to delete data that is older than 10 years Minimizes the I/O for queries that use year-to-date values
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You have several Azure Data Factory pipelines that contain a mix of the following types of activities.
* Wrangling data flow
* Notebook
* Copy
* jar
Which two Azure services should you use to debug the activities? Each correct answer presents part of the solution NOTE: Each correct selection is worth one point.
- A . Azure HDInsight
- B . Azure Databricks
- C . Azure Machine Learning
- D . Azure Data Factory
- E . Azure Synapse Analytics
HOTSPOT
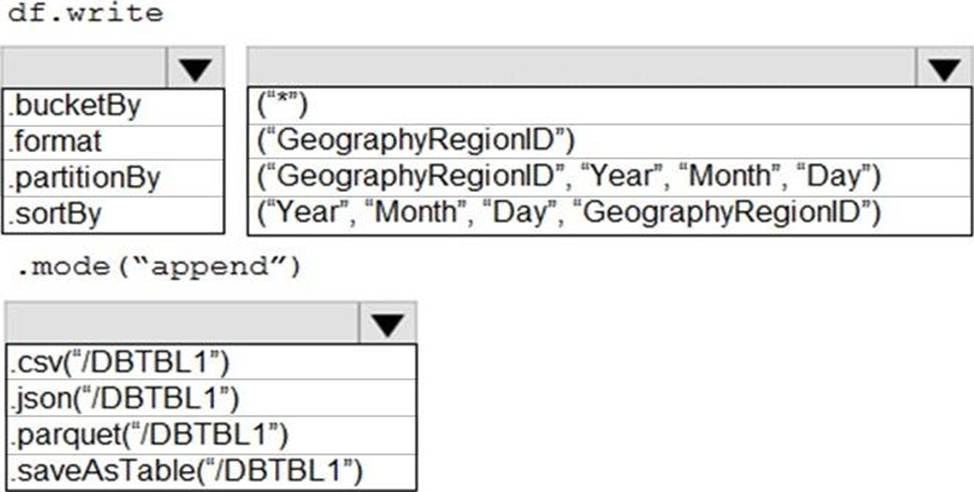
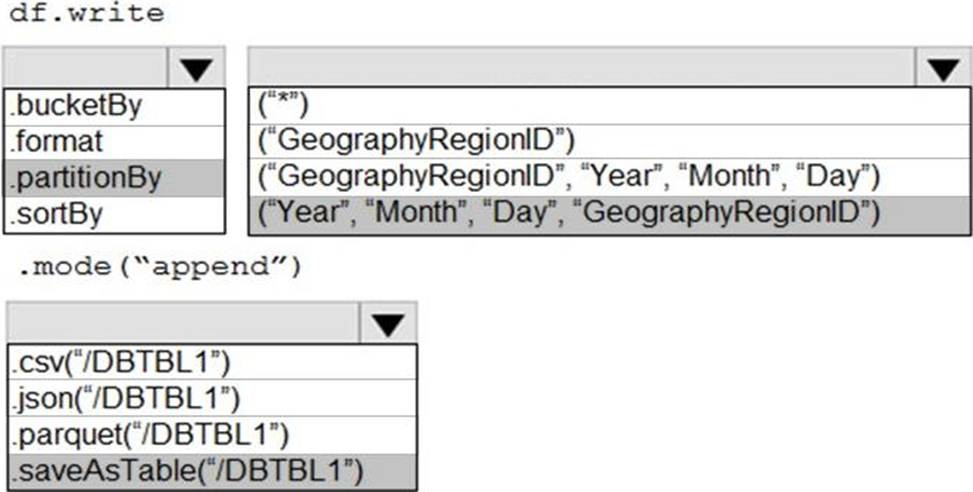
You develop a dataset named DBTBL1 by using Azure Databricks.
DBTBL1 contains the following columns:
✑ SensorTypeID
✑ GeographyRegionID
✑ Year
✑ Month
✑ Day
✑ Hour
✑ Minute
✑ Temperature
✑ WindSpeed
✑ Other
You need to store the data to support daily incremental load pipelines that vary for each GeographyRegionID. The solution must minimize storage costs.
How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
HOTSPOT
You have an Azure subscription that contains the following resources:
An Azure Active Directory (Azure AD) tenant that contains a security group named Group1 An Azure Synapse Analytics SQL pool named Pool1
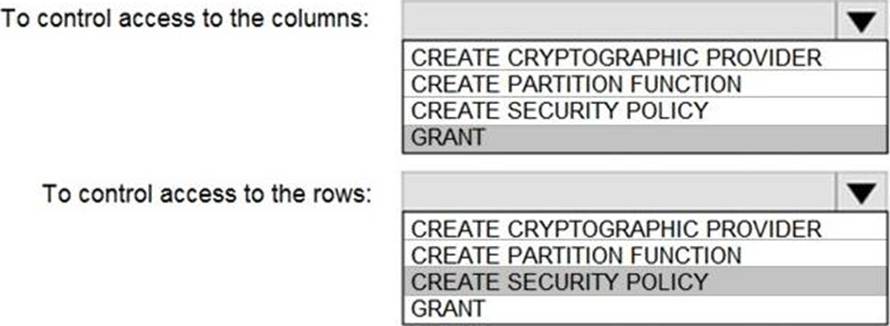
You need to control the access of Group1 to specific columns and rows in a table in Pool1.
Which Transact-SQL commands should you use? To answer, select the appropriate options in the answer area.

A company has a real-time data analysis solution that is hosted on Microsoft Azure. The solution uses Azure Event Hub to ingest data and an Azure Stream Analytics cloud job to analyze the data. The cloud job is configured to use 120 Streaming Units (SU).
You need to optimize performance for the Azure Stream Analytics job.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Implement event ordering.
- B . Implement Azure Stream Analytics user-defined functions (UDF).
- C . Implement query parallelization by partitioning the data output.
- D . Scale the SU count for the job up.
- E . Scale the SU count for the job down.
- F . Implement query parallelization by partitioning the data input.
You have an Azure Synapse Analytics dedicated SQL pool.
You plan to create a fact table named Table1 that will contain a clustered columnstore index.
You need to optimize data compression and query performance for Table1.
What is the minimum number of rows that Table1 should contain before you create partitions?
- A . 100.000
- B . 600,000
- C . 1 million
- D . 60 million
HOTSPOT
You have an Azure Synapse Analytics pipeline named pipeline1 that has concurrency set to 1.
To run pipeline 1, you create a new trigger as shown in the following exhibit.
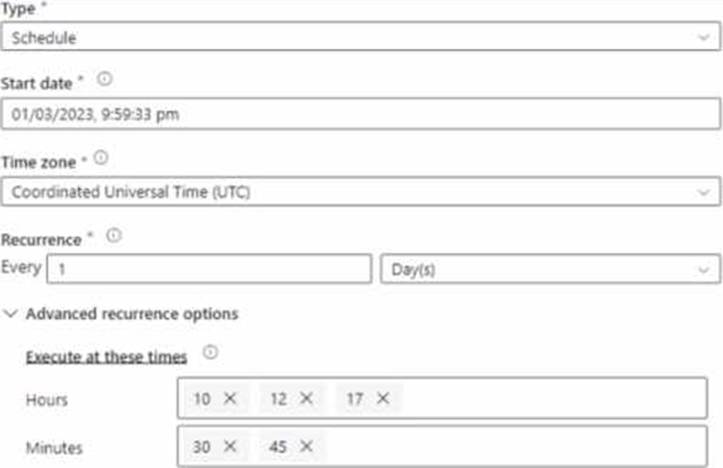
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the [graphic. NOTE: Each correct selection is worth one point.


You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and a database named DB1.
DB1 contains a fact table named Table1.
You need to identify the extent of the data skew in Table1.
What should you do in Synapse Studio?
- A . Connect to the built-in pool and query sysdm_pdw_sys_info.
- B . Connect to Pool1 and run DBCC CHECKALLOC.
- C . Connect to the built-in pool and run DBCC CHECKALLOC.
- D . Connect to Pool! and query sys.dm_pdw_nodes_db_partition_stats.