Microsoft DP-600 Übungsprüfungen
Zuletzt aktualisiert am 12.04.2026- Prüfungscode: DP-600
- Prüfungsname: Microsoft Fabric Analytics Engineer
- Zertifizierungsanbieter: Microsoft
- Zuletzt aktualisiert am: 12.04.2026
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a lakehouse named Lakehousel. Lakehousel contains a Delta table named Customer.
When you query Customer, you discover that the query is slow to execute. You suspect that maintenance was NOT performed on the table.
You need to identify whether maintenance tasks were performed on Customer.
Solution: You run the following Spark SQL statement:
DESCRIBE DETAIL customer
Does this meet the goal?
- A . Yes
- B . No
You have a Fabric tenant that contains a new semantic model in OneLake.
You use a Fabric notebook to read the data into a Spark DataFrame.
You need to evaluate the data to calculate the min, max, mean, and standard deviation values for all the string and numeric columns.
Solution: You use the following PySpark expression:
df.explain()
Does this meet the goal?
- A . Yes
- B . No
DRAG DROP
You have a Fabric tenant that contains a lakehouse named Lakehouse1
Readings from 100 loT devices are appended to a Delta table in Lakehouse1. Each set of readings is approximately 25 KB. Approximately 10 GB of data is received daily.
All the table and SparkSession settings are set to the default.
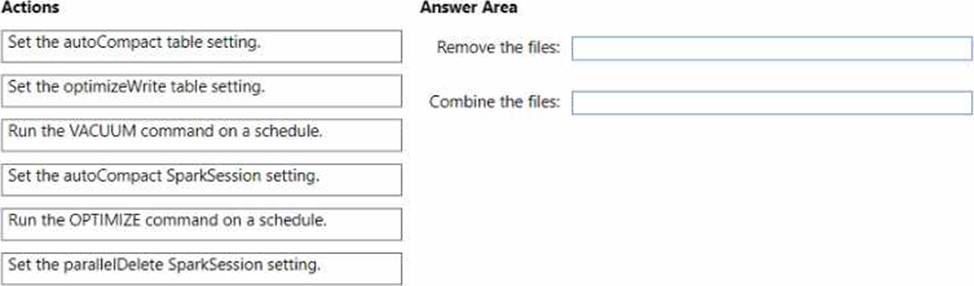
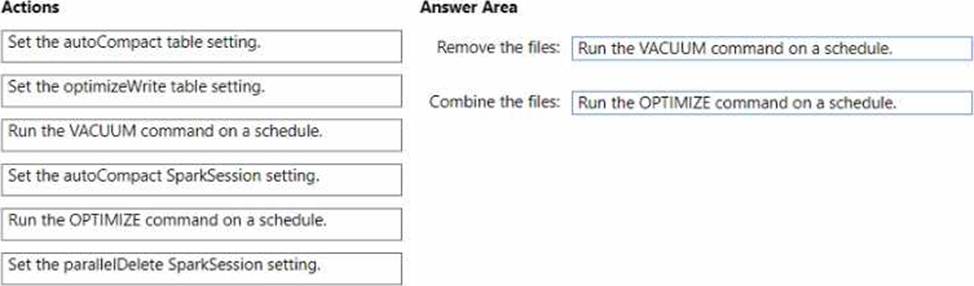
You discover that queries are slow to execute. In addition, the lakehouse storage contains data and log files that are no longer used.
You need to remove the files that are no longer used and combine small files into larger files with a target size of 1 GB per file.
What should you do? To answer, drag the appropriate actions to the correct requirements. Each action may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
HOTSPOT
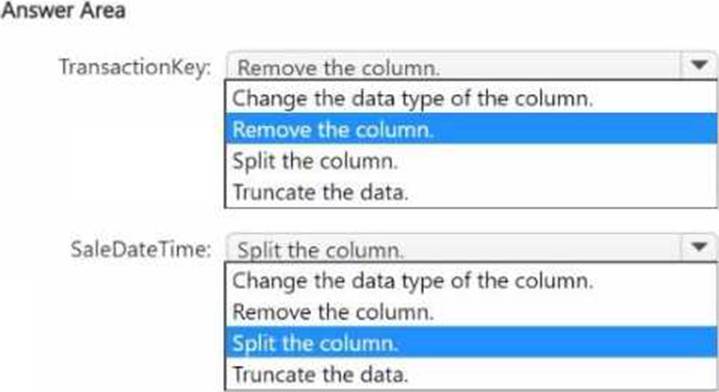
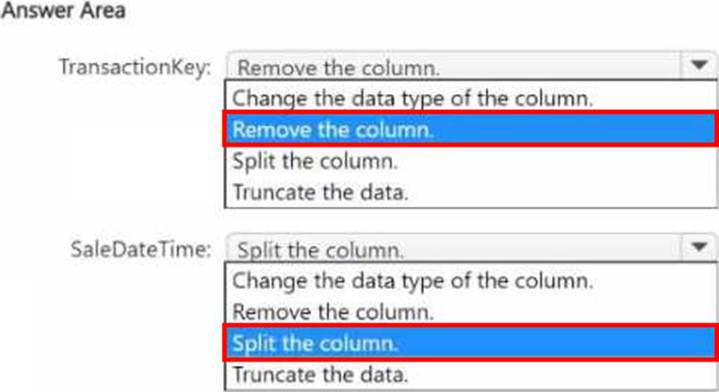
You have a Fabric tenant that contains a semantic model named model1.
The two largest columns in model1 are shown in the following table.
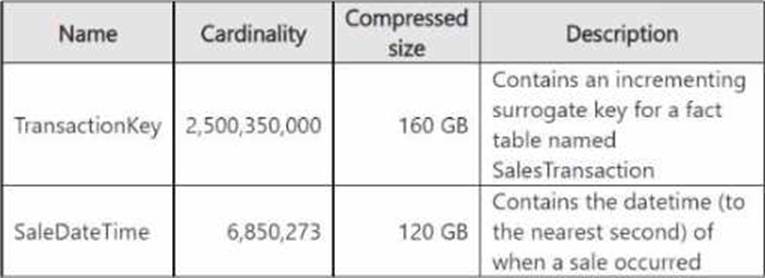
You need to optimize model 1.
The solution must meet the following requirements:
• Reduce the model size.
• Increase refresh performance when using Import mode.
• Ensure that the datetime value for each sales transaction is available in the model.
What should you do on each column? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You have a Microsoft Power Bl semantic model that contains measures. The measures use multiple calculate functions and a filter function.
You are evaluating the performance of the measures.
In which use case will replacing the filter function with the keepfilters function reduce execution time?
- A . when the filter function uses a nested calculate function
- B . when the filter function references a column from a single table that uses Import mode
- C . when the filter function references columns from multiple tables
- D . when the filter function references a measure
What should you recommend using to ingest the customer data into the data store in the AnatyticsPOC workspace?
- A . a stored procedure
- B . a pipeline that contains a KQL activity
- C . a Spark notebook
- D . a dataflow
You have a Fabric tenant that contains a lakehouse named Lakehouse1. Lakehouse1 contains a subfolder named Subfolder1 that contains CSV files. You need to convert the CSV files into the delta format that has V-Order optimization enabled.
What should you do from Lakehouse explorer?
- A . Use the Load to Tables feature.
- B . Create a new shortcut in the Files section.
- C . Create a new shortcut in the Tables section.
- D . Use the Optimize feature.
You are the administrator of a Fabric workspace that contains a lakehouse named Lakehouse1.
Lakehouse1 contains the following tables:
• Table1: A Delta table created by using a shortcut
• Table2: An external table created by using Spark
• Table3: A managed table
You plan to connect to Lakehouse1 by using its SQL endpoint.
What will you be able to do after connecting to Lakehouse1?
- A . ReadTable3.
- B . Update the data Table3.
- C . ReadTable2.
- D . Update the data in Table1.
You have a Fabric tenant that contains a semantic model named Model1. Model1 uses Import mode.
Model1 contains a table named Orders.
Orders has 100 million rows and the following fields.
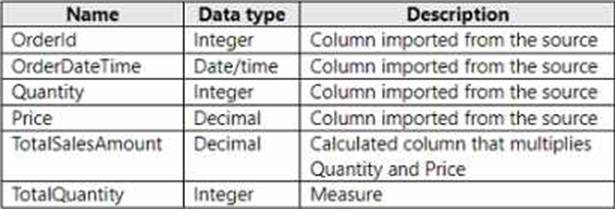
You need to reduce the memory used by Model! and the time it takes to refresh the model.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct answer is worth one point.
- A . Split OrderDateTime into separate date and time columns.
- B . Replace TotalQuantity with a calculated column.
- C . Convert Quantity into the Text data type.
- D . Replace TotalSalesAmount with a measure.
DRAG DROP
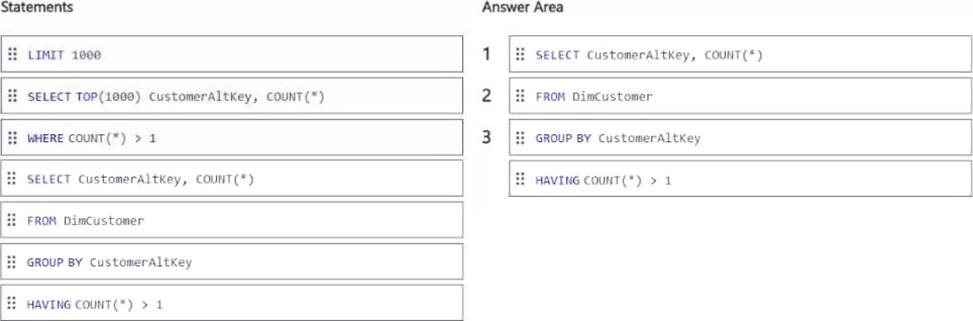
You have a Fabric tenant that contains a data warehouse named DW1. DW1 contains a table named DimCustomer.
DimCustomer contains the fields shown in the following table.
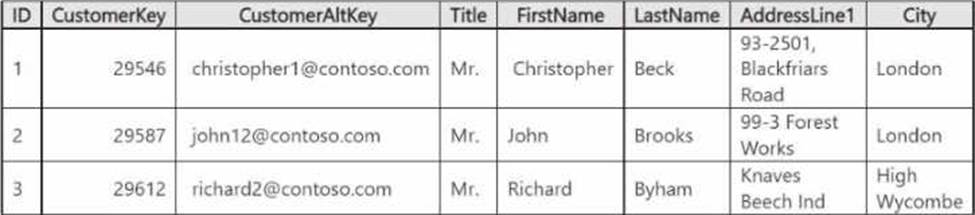
You need to identify duplicate email addresses in DimCustomer. The solution must return a maximum of 1,000 records.
Which four T-SQL statements should you run in sequence? To answer, move the appropriate statements from the list of statements to the answer area and arrange them in the correct order.