Microsoft DP-700 Übungsprüfungen
Zuletzt aktualisiert am 26.04.2025- Prüfungscode: DP-700
- Prüfungsname: Microsoft Fabric Data Engineer
- Zertifizierungsanbieter: Microsoft
- Zuletzt aktualisiert am: 26.04.2025
HOTSPOT
You have a Fabric workspace named Workspace1_DEV that contains the following items:
– 10 reports
– Four notebooks
– Three lakehouses
– Two data pipelines
– Two Dataflow Gen1 dataflows
– Three Dataflow Gen2 dataflows
– Five semantic models that each has a scheduled refresh policy
You create a deployment pipeline named Pipeline1 to move items from Workspace1_DEV to a new workspace named Workspace1_TEST.
You deploy all the items from Workspace1_DEV to Workspace1_TEST.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


You have an Azure event hub.
Each event contains the following fields:
BikepointID
Street
Neighbourhood
Latitude
Longitude
No_Bikes
No_Empty_Docks
You need to ingest the events. The solution must only retain events that have a Neighbourhood value of Chelsea, and then store the retained events in a Fabric lakehouse.
What should you use?
- A . a KQL queryset
- B . an eventstream
- C . a streaming dataset
- D . Apache Spark Structured Streaming
HOTSPOT
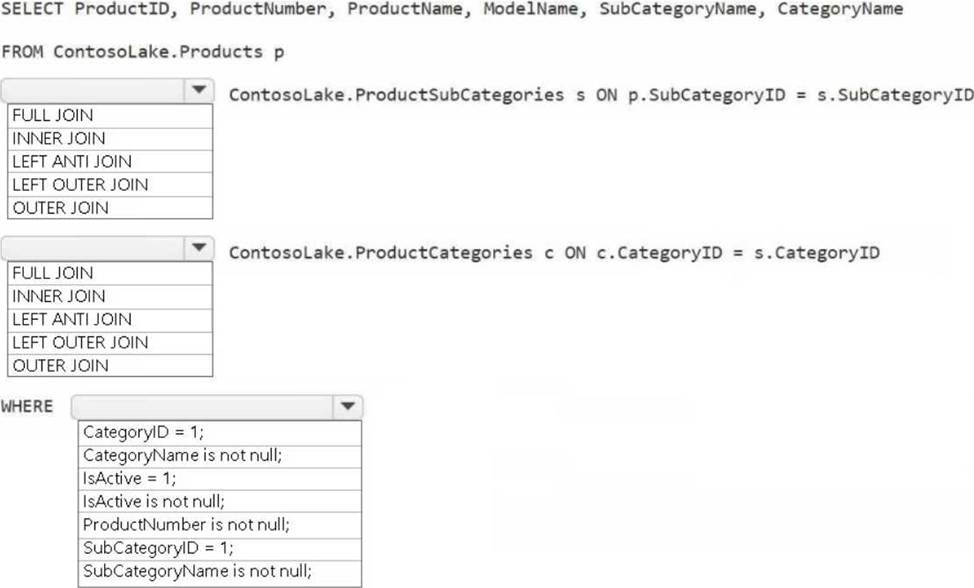
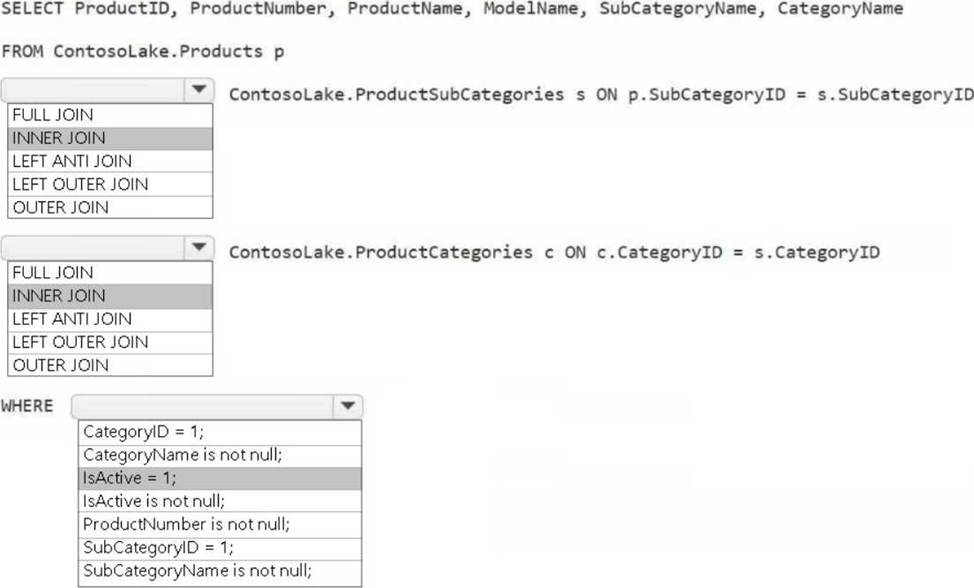
You need to create the product dimension.
How should you complete the Apache Spark SQL code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You have a Fabric workspace that contains a semantic model named Model1. You need to dynamically execute and monitor the refresh progress of Model1.
What should you use?
- A . dynamic management views in Microsoft SQL Server Management Studio
- B . Monitoring hub
- C . dynamic management views in Azure Data Studio
- D . a semantic link in a notebook
HOTSPOT
You are building a data loading pattern for Fabric notebook workloads.
You have the following code segment:

For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


You have a Fabric workspace named Workspace1 that contains a data pipeline named Pipeline1 and a lakehouse named Lakehouse1.
You have a deployment pipeline named deployPipeline1 that deploys Workspace1 to Workspace2.
You restructure Workspace1 by adding a folder named Folder1 and moving Pipeline1 to Folder1.
You use deployPipeline1 to deploy Workspace1 to Workspace2.
What occurs to Workspace2?
- A . Folder1 is created, Pipeline1 moves to Folder1, and Lakehouse1 is deployed.
- B . Only Pipeline1 and Lakehouse1 are deployed.
- C . Folder1 is created, and Pipeline1 and Lakehouse1 move to Folder1.
- D . Only Folder1 is created and Pipeline1 moves to Folder1.
You have a Fabric capacity that contains a workspace named Workspace1. Workspace1 contains a lake house named Lakehouse1, a data pipeline, a notebook, and several Microsoft Power BI reports.
A user named User1 wants to use SQL to analyze the data in Lakehouse1.
You need to configure access for User1.
The solution must meet the following requirements:
– Provide User1 with read access to the table data in Lakehouse1.
– Prevent User1 from using Apache Spark to query the underlying files in Lakehouse1.
– Prevent User1 from accessing other items in Workspace1.
What should you do?
- A . Share Lakehouse1 with User1 directly and select Read all SQL endpoint data.
- B . Assign User1 the Viewer role for Workspace1. Share Lakehouse1 with User1 and select Read all SQL endpoint data.
- C . Share Lakehouse1 with User1 directly and select Build reports on the default semantic model.
- D . Assign User1 the Member role for Workspace1. Share Lakehouse1 with User1 and select Read all SQL endpoint data.